

The new Unravel 4.5 release expands your ability to operationalize modern data pipelines at significantly higher levels of complexity and scale.
The Unravel 4.5 release, now generally available, builds on our previous 4.4 release with enhanced reporting, expanded SQL insights, and improved RESTful APIs.
Enhanced Reporting
Unravel 4.5 features new reports for “TopX”, queue analysis, cloud migration, and enhancements to the existing reports such as forecasts and chargeback.
TopX Reports
[under Data Insights]
When you’re managing big data clusters, you have many ongoing operational and application challenges. Wouldn’t it be easier if you were notified daily/weekly/monthly about the top applications that you need to uncover-> understand->unravel?
Unravel’s TopX reports provide you with precisely this service. When you schedule a Top X report, Unravel generates a list of the top X (where 0 < X < 100) applications – whether they are Hive-on-MapReduce, Hive-on-Tez, or Spark – organized by categories, such as:
Data I/O
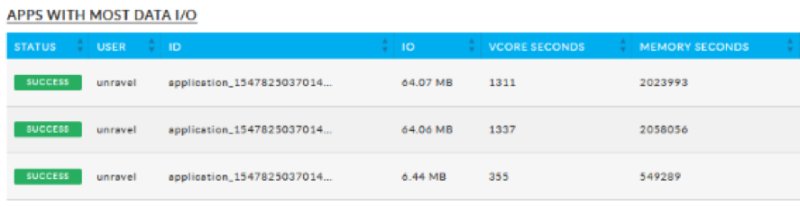
Cluster Usage
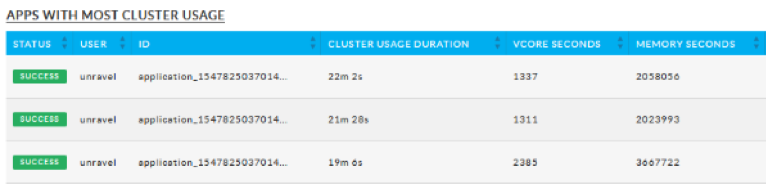
Duration
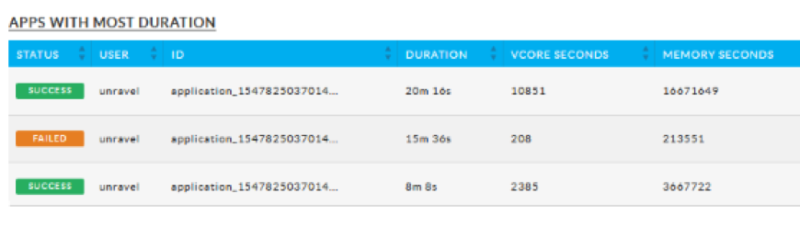
Within these reports, you can drill down into the APM view for each app, identify any inefficiencies and their root causes, and understand how to tune/optimize the app.
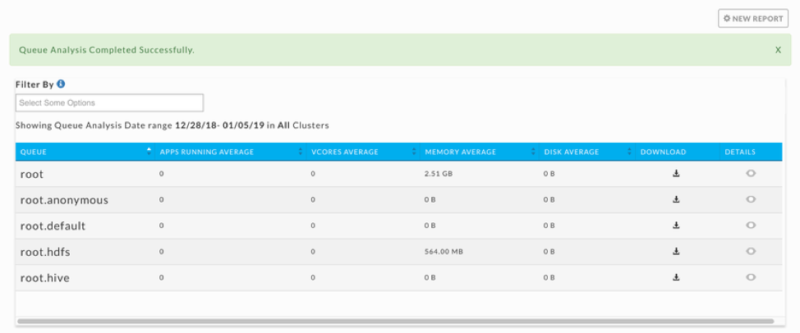
Queue Analysis Reports
[Under Operational Insights]
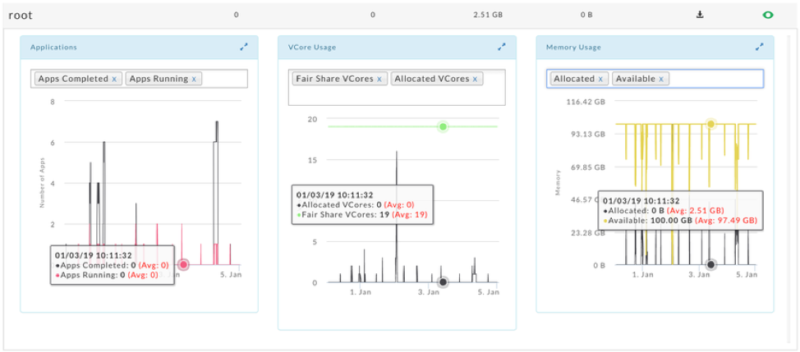
Queue Analysisreports shine light on how you’re using queues and how you can tune them for optimal usage. These reports analyze queue activity with respect to applications, vcores, memory, and disk. As with all reports, you can generate Queue Analysis reports on an ad hoc or on a scheduled basis.
Cloud Migration Reporting
Unravel 4.5 also includes several new reports aimed at helping organizations move their big data workloads to the cloud (either onto an IaaS platform or onto a cloud native platform like AWS EMR, Azure HDInsight, etc.). These reports help organizations in planning -> migrating -> managing their big data workloads. Here’s a quick preview on these new reports
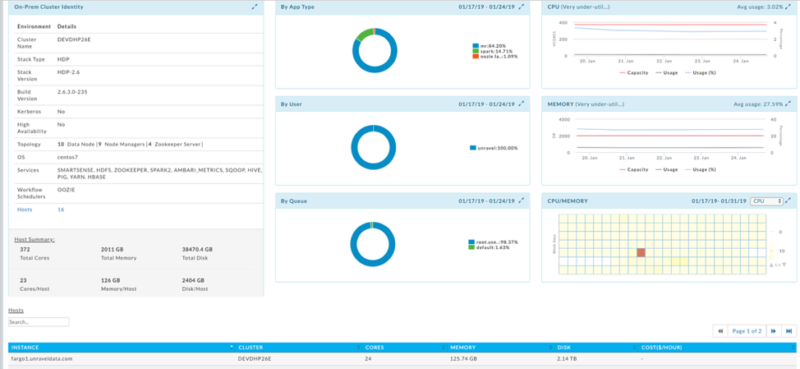
Cluster Discovery Report
Unravel provides a single pane of glass to display all of the relevant information e.g., services deployed, the topology of the cluster, cluster level stats (which have been suitably aggregated over the entire cluster’s resources) in terms of CPU, memory and disk. The across-cluster heatmaps display the relative utilization of the cluster across time (a 24×7 view for each hour of say a week).
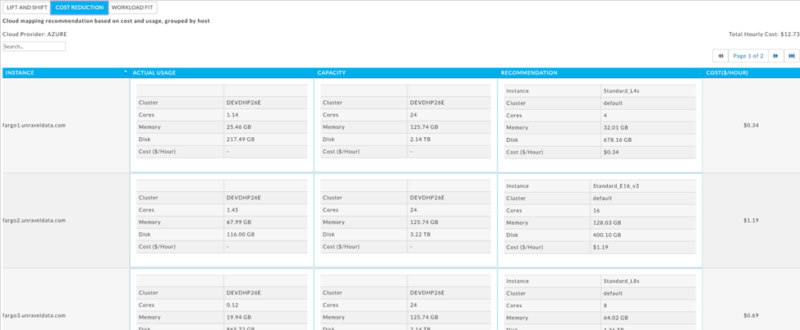
Cloud Mapping Reports
Unravel provides you a mapping of your current on-prem environment to a cloud based one. Cloud Mapping Reports tell you the precise details of what type of cloud instances you would need, how many and what it would cost you. Here’s the mapping based on the strategy we refer to as “Cost Reduction” that provides you a one to one mapping of each existing on-prem host to the most suitable instance type in the cloud such that it matches the actual resource usage on-prem.
Stay tuned for new blogs on this topic in the coming weeks!
In addition to our new reports, we’ve enhanced our Forecasting, Chargeback, and Small Files reports for speed/performance and with support for additional frameworks (Impala, Tez) and platforms (MapR).
Live Applications
You spoke, we listened. A frequent request from customers has been to
- Show more insights into running applications
- Give the ability to take actions on running applications
As part of 4.5, Unravel now shows the progress (%) of individual jobs in a Spark app:
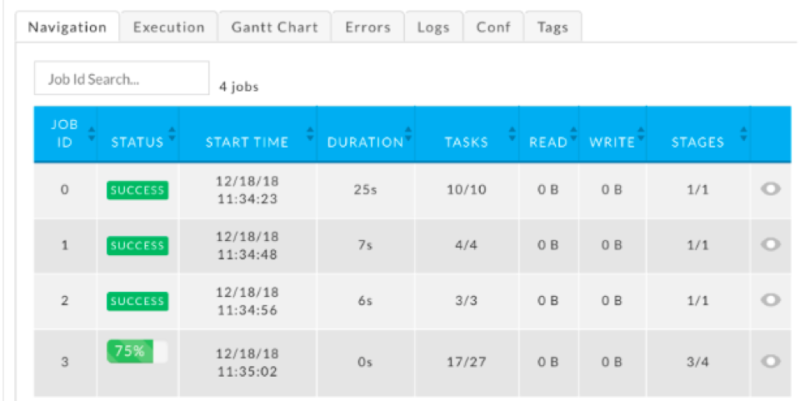
And, when you see a running YARN app (Spark, MR, and Tez) that’s taking far too much time (for issues related to data skew, slow nodes, etc.), you can now kill it or move it to a different YARN queue.
SQL Insights
We continue to add more insights and recommendations for SQL engines like Tez and Impala. Some specific improvements for Hive/Tez apps include:
- Improvements in “map tasks” recommendations for Hive/Tez apps
- Improvements in recommendations for Hive/Tez apps
- Improvements in failure events for Hive/Tez apps
- Out-of-memory errors (including recommendations for increasing the JVM settings)
- “Block missing” errors (for example, when an HDFS disk is missing or corrupted)
- “Illegal argument” errors (for example, tez.runtime.io.sort.mb or hive.tez.java.opts set outside the memory limits)
- Internal Tez errors raised as unchecked exceptions
Some of the improvements for Impala include:
- Improvements in “time breakdown” events to help you identify the bottleneck phase during the execution of an Impala query, specifically for slow query planning, slow row fetching, and slow clients
- Data insights related to large tables without partitions or too many (>30K) partitions
- Improvements in “slow operator” events related to:
- Checks for slow processing rates (for example, sorting throughput is less than 10M rows/sec)
- Checks for disk spilling
- Cartesian products
- Joins across large tables
- Aggregations with more than 10 columns in the “group by” clause
- New SQL-level events related to:
- Queries with no filter
- Queries with too many joins
- Queries with too many join conditions
Unravel RESTful APIs
Unravel’s RESTful APIs provide an easy way to access the rich information collected and correlated by Unravel. Developers can access KPIs, metrics, alerts, etc. and integrate that data with other systems or tools already in use such as Slack, PagerDuty, Nagios, ServiceNow, etc.
As part of this release, we’ve made several enhancements to our existing API, including several new endpoints allowing you to:
- Get insights on individual apps
- Get status, errors, logs, and summaries of individual apps
Much More
Finally, I have highlighted just some of the key features in Unravel 4.5. This release also includes other updates like Auto Actions for Impala and Tez apps, support for SSO/SAML, security fixes, UI fixes, and many enhancements!
The Unravel 4.5 release is available on all supported platforms and works identically on-premises and in the cloud (Amazon AWS/EMR, Microsoft Azure, Google Cloud Platform).
Try Unravel today. Create a free account.