

Table of Contents
As anyone running modern data applications in the cloud knows, costs can mushroom out of control very quickly and easily. Getting these costs under control is really all about not spending more than you have to. Unfortunately, the common approach to managing these expenses—which looks at things only at an aggregated infrastructure level—helps control only about 5% of your cloud spend. You’re blind to the remaining 95% of cost-saving opportunities because there’s a huge gap in your ability to understand exactly what all your applications, pipelines, and users are doing, how much they’re costing you (and why), and whether those costs can be brought down.
Controlling cloud costs has become a business imperative for any enterprise running modern data stack applications. Industry analysts estimate that at least 30% of cloud spend is “wasted” each year—some $17.6 billion. For modern data pipelines in the cloud, the percentage of waste is much higher—closer to 50%.
This is because cloud providers have made it so much easier to spin up new instances, it’s also much easier for costs to spiral out of control. The sheer size of modern data workloads amplifies the problem exponentially. We recently saw a case where a single sub-optimized data job that ran over the weekend wound up costing the company an unnecessary $1 million. But the good news is that there are a lot of opportunities for you to save money.
Every data team and IT budget holder recognizes at an abstract, theoretical level what they need to do to control data cloud costs:
- Shut off unused always-on resources (idle clusters)
- Leverage spot instance discounts
- Optimize the configuration of auto-scaling data jobs
Understanding what to do in principle is easy. Knowing where, when, and how to do it in practice is far more complicated. And this is where the common cost-management approach for modern data clouds falls short.
What’s needed is a new approach to controlling modern data cloud costs—a “workload aware” approach that harnesses precise, granular information at the application level to develop deep intelligence about what workloads you are running, who’s running them, which days and time of day they run, and, most important, what resources are actually required for each particular workload.
Pros and Cons of Existing Cloud Cost Management
Allocating Costs—Okay, Not Great
The first step to controlling costs is, of course, understanding where the money is going. Most approaches to cloud cost management today focus primarily on an aggregated view of the total infrastructure expense: monthly spend on compute, storage, platform, etc. While this is certainly useful from a high-level, bird’s-eye view for month-over-month budget management, it doesn’t really identify where the cost-saving opportunities lie. Tagging resources by department, function, application, user etc., is a good first step in understanding where the money is going, but tagging alone doesn’t help you understand if the cost is good or bad—and whether it could be brought down (and how).
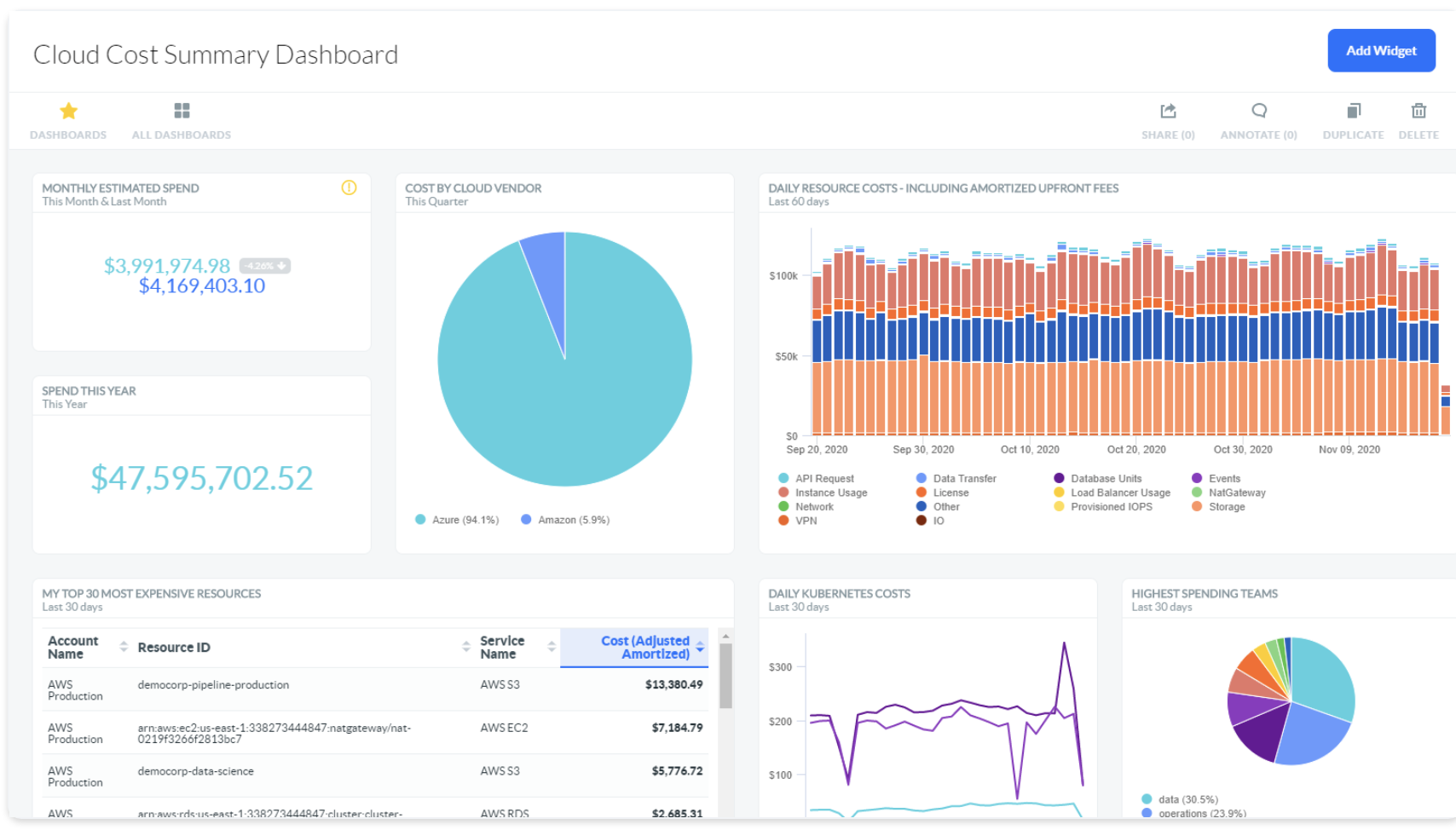
Here’s a cloud budget management dashboard that does a good job of summarizing at a high level where cloud spend is going. But where could costs be brought down?
Native cloud vendor tools (and even some third-party solutions) can break down individual instance costs—how much you’re spending on each machine—but don’t tell you which jobs or workflows are running there. It’s just another view of the same unanswered question: Are you overspending?
Eliminating Idle Resources—Good
When it comes to shutting down idle clusters, all the cloud platform providers (AWS, Azure, Google Cloud Platform, Databricks), as well as a host of so-called cloud cost management tools from third-party vendors, do a really good job of identifying resources you’re not using anymore and can terminate them automatically.
Reducing Costs—Poor
Where many enterprises’ approach leaves a lot to be desired revolves around resource and application optimization. This is where you can save the big bucks—specifically, reducing costs with spot instances and auto-scaling, for example—but it requires a new approach.
Check out the Unravel approach to controlling cloud costs
A Smarter “Workload-Aware” Approach
An enterprise with 100,000+ modern data jobs has literally a million decisions—at the application, pipeline, and cluster level—to make about where, when, and how to run those jobs. And each individual decision carries a price tag.
Preventing Overspending
The #1 culprit in data cloud overspending is overprovisioning/underutilizing instances.
Every enterprise has thousands and thousands of jobs that are running on more expensive instances than necessary. Either more resources are requested than actually needed or the instances are larger than needed for the job at hand. Frequently the resources allocated to run jobs in the cloud are dramatically different than what is actually required, and those requirements can vary greatly depending upon usage patterns or seasonality. Without visibility into the actual resource requirements of each job over time, it is just a guessing game which level of machine to allocate in the cloud.
That’s why a more effective approach to controlling cloud costs must start at the job level. Whichever data team members are requesting instances must be empowered with accurate, easy-to-understand metrics about actual usage requirements—CPU, memory, I/O, duration, containers, etc.—so that they can specify right-sized configurations based on actual utilization requirements rather than having to “guesstimate” based on perceived capacity need.
For example, suppose you’re running a Spark job and estimate that you’ll need six containers with 32 GB of memory. That’s your best guess, and you certainly don’t want to get “caught short” and have the job fail. But if you had application-level information at your fingertips that in reality you need only three containers that use only 5.2 GB of memory (max), you could request a right-sized instance configuration and avoid unnecessarily overspending. Instead of paying, say, $1.44 for a 32GB machine (x6), you pay only $0.30 for a 16GB machine (x3). Multiply the savings across several hundred users running hundreds of thousands of jobs every month, and you’re talking big bucks.
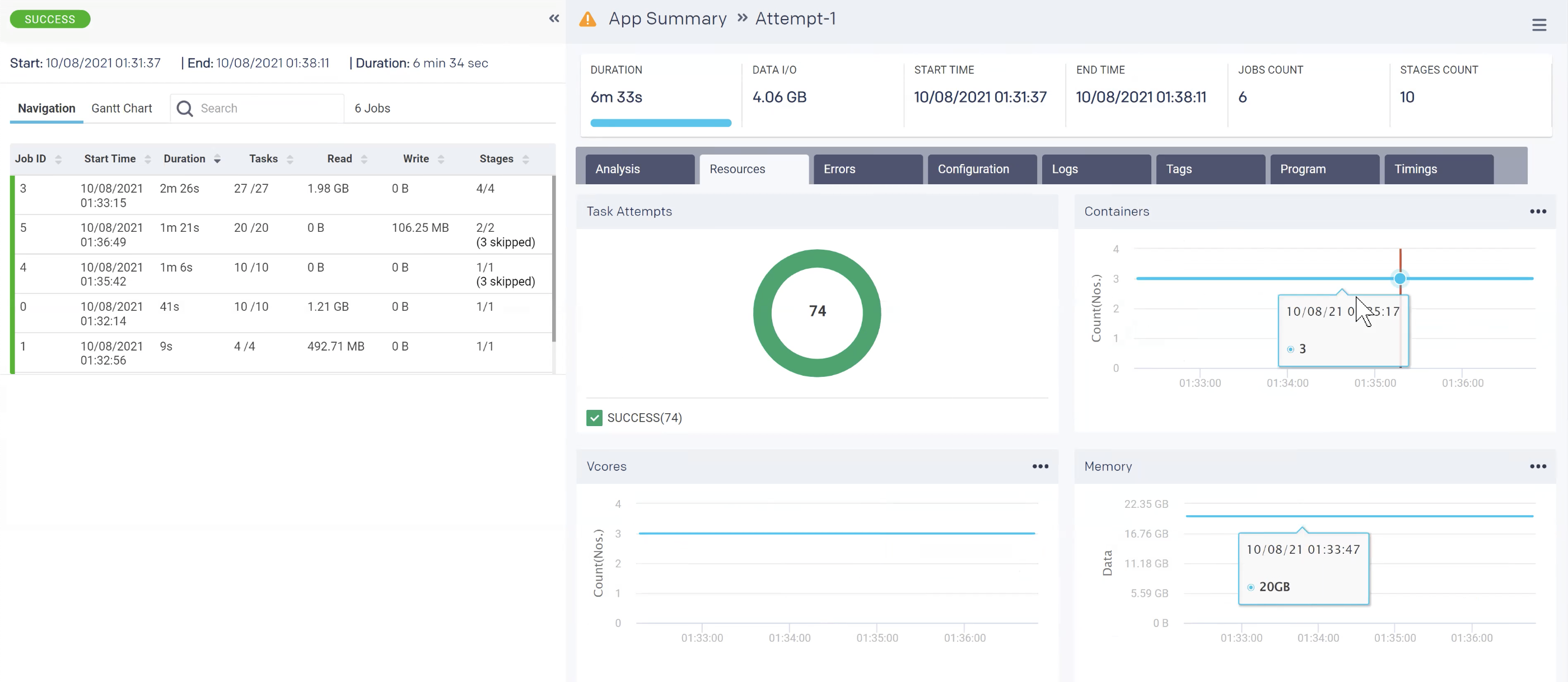
Application-level intelligence about actual utilization allows you specify with precision the number and size of instances really needed for the job at hand.
Further, a workload-aware approach that has application-level intelligence also can also tell you how long the job ran for.
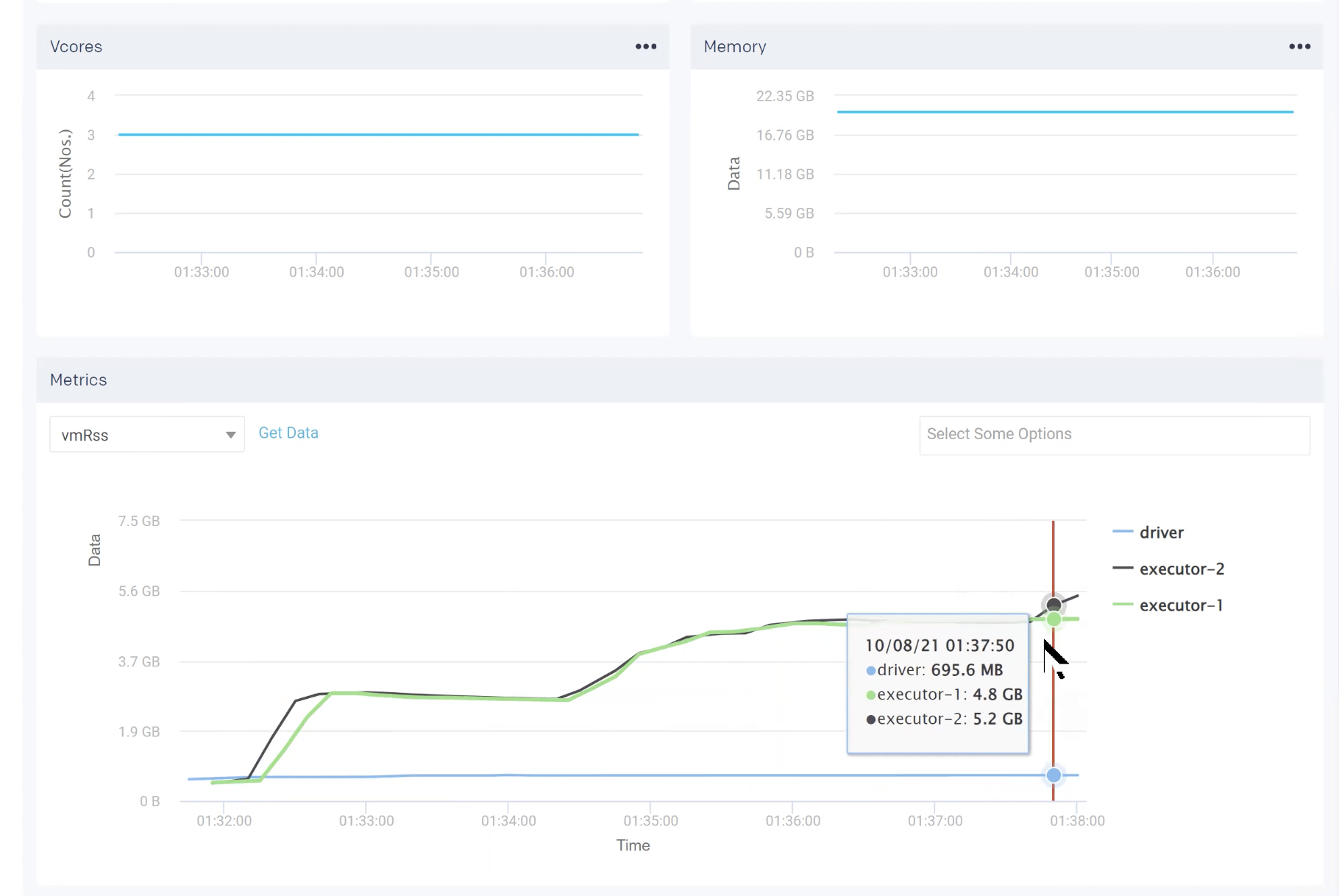
Knowing the duration of each job empowers you to shut down clusters based on execution state rather than waiting for an idle state.
Here, you can see that this particular job took about 6½ minutes to run. With this intelligence, you know exactly how long you need this instance. You can tell when you can utilize the instance for another job or, even better, shut it down altogether.
Leveraging Spot Instances
This really helps with determining when to use spot instances. Everybody wants to take advantage of spot instance pricing discounts. While spot instances can save you big bucks—up to 90% cheaper than on-demand pricing—they come with the caveat that the cloud provider can “pull the plug” and terminate the instance with as little as a 30-second warning. So, not every job is a good candidate to run on spot. A simple SQL query that takes 10-15 seconds is great. A 3-hour job that’s part of a larger pipeline workflow, not so much. Nobody wants their job to terminate after 2½ hours, unfinished. The two extremes are pretty easy yes/no decisions, but that leaves a lot of middle ground. Actual utilization information at the job level is needed to know what you can run on spot (and, again, how many and what size instances) without compromising reliability. One of the top questions cloud providers hear from their customers is how to know what jobs can be run safely on spot instances. App-level intelligence that’s workload-aware is the only way.
Auto-Scaling Effectively
This granular app-level information can also be leveraged at the cluster level to know with precision how, when, and where to take advantage of auto-scaling. One of the main benefits of the cloud is the ability to auto-scale workloads, spinning up (and down) resources as needed. But this scalability isn’t free. You don’t want to spend more than you absolutely have to. A heatmap like the one below shows how many jobs are running at each time of the day on each day of the week (or month or whatever cadence is appropriate), with drill-down capabilities into how much memory and CPU is needed at any given point in time. You avoid guesstimating configurations based on perceived capacity needs rather than precisely specifying resources based on actual usage requirements. Once you understand what you really need, you can tell what you don’t need.
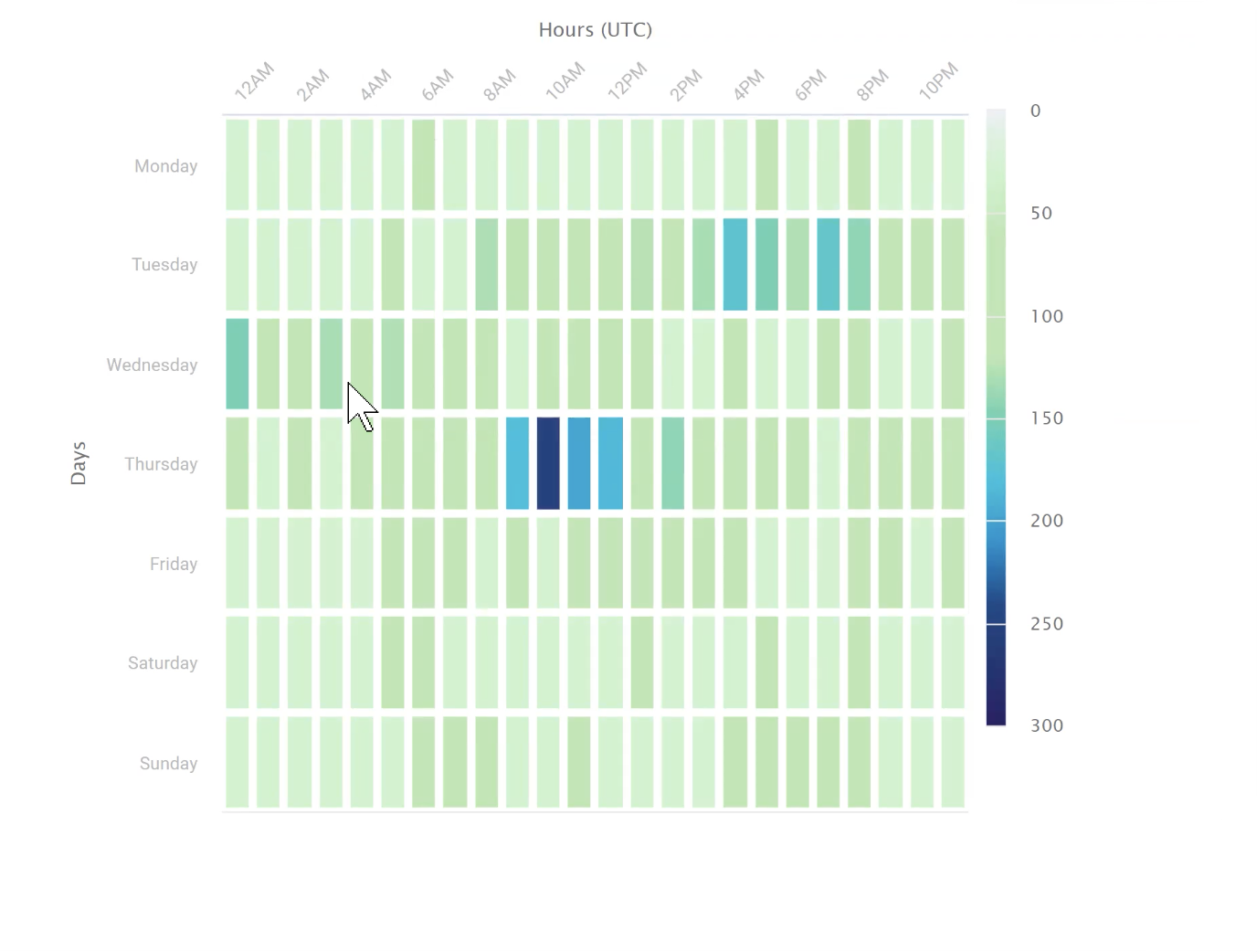
To take advantage of cost savings with auto-scaling, you have to know exactly when you need max capacity and for how long—at the application level.
Unravel is full-stack “workload-aware”
Conclusion
Most cloud cost management tools on the market today do a pretty good job of aggregating cloud expenses at a high level, tracking current spend vs. budget, and presenting cloud provider pricing options (i.e., reserved vs. on-demand vs. spot instances). Some can even go a step further and show you instance-level costs, what you’re spending machine by machine. While this approach has some (limited) value for accounting purposes, it doesn’t help you actually control costs.
When talking about “controlling costs,” most budget holders are referring to the bottom-line objective: reducing costs, or at least not spending more than you have to. But for that, you need more than just aggregated information about infrastructure spend, you need application-level intelligence about all the individual jobs that are running, who’s running them (and when), and what resources each job is actually consuming compared to what resources have been configured.
As much as 50% of data cloud instances are overprovisioned. When you have 100,000s of jobs being run by thousands of users—most of whom “guesstimate” auto-scaling configurations based on perceived capacity needs rather than on actual usage requirements—it’s easy to see how budgets blow up. Trying to control costs by looking at the overall infrastructure spend is impossible. Only by knowing with precision at a granular job level what you do need can you understand what you don’t need and trim away the fat.
To truly control data cloud costs, not just see how much you spent month over month, you need to tackle things with a bottom-up, application-level approach rather than the more common top-down, infrastructure-level method.
See what a “workload-aware” approach to controlling modern data pipelines in the cloud looks like. Create a free account.