

There are now dozens of AWS cost optimization tools that exist today. Here’s the purpose-built one for AWS EMR: Begin monitoring immediately to gain control of your AWS EMR costs and continuously optimize resource performance.
What is Amazon EMR (Elastic MapReduce)?
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto.
Based on the workload and the application type, EMR can process a huge amount of data by using EC2 instances running the Hadoop File System (HDFS) and EMRFS based on AWS S3. Based on the workload type, these EC2 instances can be configured with any instance types of on-demand and/or spot market kind.
AWS EMR is a great platform, as more and more workloads get added to it then understanding pricing can be a challenge. It’s challenging to govern the cost and easy to lose track of aspects of your monthly spend. In this article, we are sharing tips for governing and optimizing your AWS EMR costs, and resources.
Amazon EMR costs
With multiple choices in selecting instance types and configuring the EMR cluster, understanding pricing of EMR service can become cumbersome and difficult. And because the EMR service inherently utilizes other AWS services (EC2, EBS, EMR, others) so the usage cost of all these services too gets factored into the cost bill.
Best practices for optimizing the cost of your AWS EMR cluster
Here are the list of best practices/techniques for monitoring and optimizing the cost of your EMR cluster:
1. Always tag your resources
Tags is a label consisting of key-value pairs, which allows one to assign metadata to their AWS resources. And, providing one the ability to easily manage, identify, organize, search for, and filter resources. Thus, it is important to give a meaningful and purpose built tags
For example: Create tags to categorize resources by purpose, owner, department, or other criteria as shown below
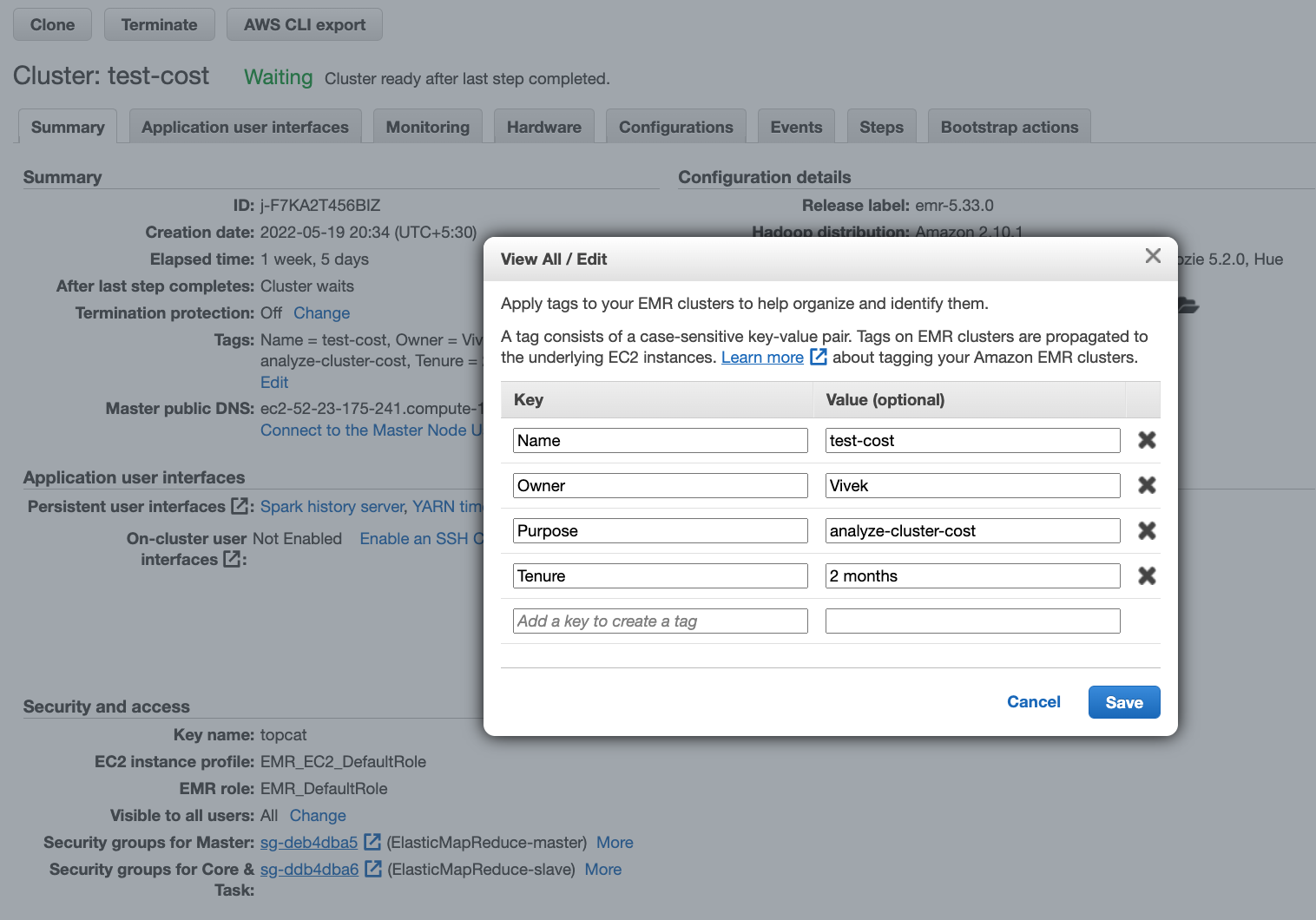
2. Pick the right cluster type
AWS EMR offers two cluster types – permanent and transient.
For transient clusters, the compute unit is decoupled from the storage. HDFS on local storage is best used for caching the intermediate results and EMRFS is the final destination for storing persistent data in AWS S3. Once the computation is done and the results are stored safely in AWS S3, the resources on transient clusters can be reclaimed.
For permanent clusters, the data in HDFS is stored in EBS volumes, and can not easily be shared outside of the clusters. Small file issues in Hadoop Name Nodes will still be present just as the on-premise Hadoop clusters.
3. Size your cluster appropriately
Undersized or oversized clusters are what you need to absolutely avoid. EMR platform provides you with auto-scaling capabilities, however, it is important to first factor in the right-sizing aspect for your clusters so as to avoid higher costs and workload execution inefficiencies. To anticipate these issues, you can calculate the number and type of nodes that will be needed for the workloads.
Master node: As the computational requirements are low for this node so it can be a single node.
Core node: As these nodes perform the data processing and storing of data in the HDFS so it is important to right size these nodes. As per Amazon guiding principle, you can multiply the number of nodes by the EBS storage capacity of each node.
For example, if you define 10 core nodes to process 1 TB of data, and you have selected m5.xlarge instance type (with 64 GiB of EBS storage), you have 10 nodes*64 GiB, or 640 GiB of capacity. Based on the HDFS replication factor of three, your data size is replicated three times in the nodes, so 1 TB of data requires a capacity of 3 TB.
For above scenario, you have two options:
a. As you have only 640 GiB here so to run your workload optimally you must increase the number of nodes or change the instance type until you have a capacity of 3 TB.
b. Alternatively, switching your instance type from m5.xlarge to an m5.4xlarge instance type and selecting 12 instances provides enough capacity.
12 instances * 256 GiB = 3072 GiB = 3.29 TB available
Task node: As these nodes only run tasks and do not store data so to calculate the number of task nodes, you only need to estimate the memory usage. As this memory capacity can be distributed between the core and task nodes, it is easy to calculate the number of task nodes by subtracting the core node memory.
As per Amazon provided best practices guidelines, you need to multiply the memory needed by three.
For example, suppose that you have 28 processes of 20 GiB each then your total memory requirements would be as follows:
3*28 processes*20 GiB of memory = 1680 GiB of memory
For this example, your core nodes have 64 GiB of memory (m5.4xlarge instances), and your task nodes have 32 GiB of memory (m5.2xlarge instances). Your core nodes provide 64 GiB * 12 nodes = 768 GiB of memory, which is not enough in this example. To find the shortage, subtract this memory from the total memory required: 1680 GiB – 768 GiB = 912 GiB. You can set up the task nodes to provide the remaining 912 GiB of memory. Divide the shortage memory by the instance type memory to obtain the number of task nodes needed.
912 GiB / 32 GiB = 28.5 task nodes
4. Based on your workload size, always pick the right instance type and size

Let us take an example of Task node where suppose that you have 28 processes of 20 GiB each then your total memory requirements would be as follows:
3*28 processes*20 GiB of memory = 1680 GiB of memory
For this example, suppose your core nodes have 64 GiB of memory (m5.4xlarge instances), and your task nodes have 32 GiB of memory (m5.2xlarge instances). Your core nodes provide 64 GiB * 12 nodes = 768 GiB of memory, which is not enough in this example.
To find the shortage, subtract this memory from the total memory required: 1680 GiB – 768 GiB = 912 GiB. You can set up the task nodes to provide the remaining 912 GiB of memory. Divide the shortage memory by the instance type memory to obtain the number of task nodes needed.
912 GiB / 32 GiB = 28.5 task nodes
5. Use autoscaling as needed
Based on your workload size, Amazon EMR can programmatically scale out applications like Apache Spark and Apache Hive to utilize additional nodes for increased performance and scale in the number of nodes in your cluster to save costs when utilization is low.
For example, you can assign minimum, maximum, on-demand limit and maximum core node to dynamically scale up and down based on your running workload.

6. Always have a cluster termination policy set
When you add an auto-termination policy to a cluster, you specify the amount of idle time after which the cluster should automatically shut down. This ability allows you to orchestrate cluster cleanup without the need to monitor and manually terminate unused clusters.

You can attach an auto-termination policy when you create a cluster, or add a policy to an existing cluster. To change or disable auto-termination, you can update or remove the policy.
7. Monitor cost with cost explorer
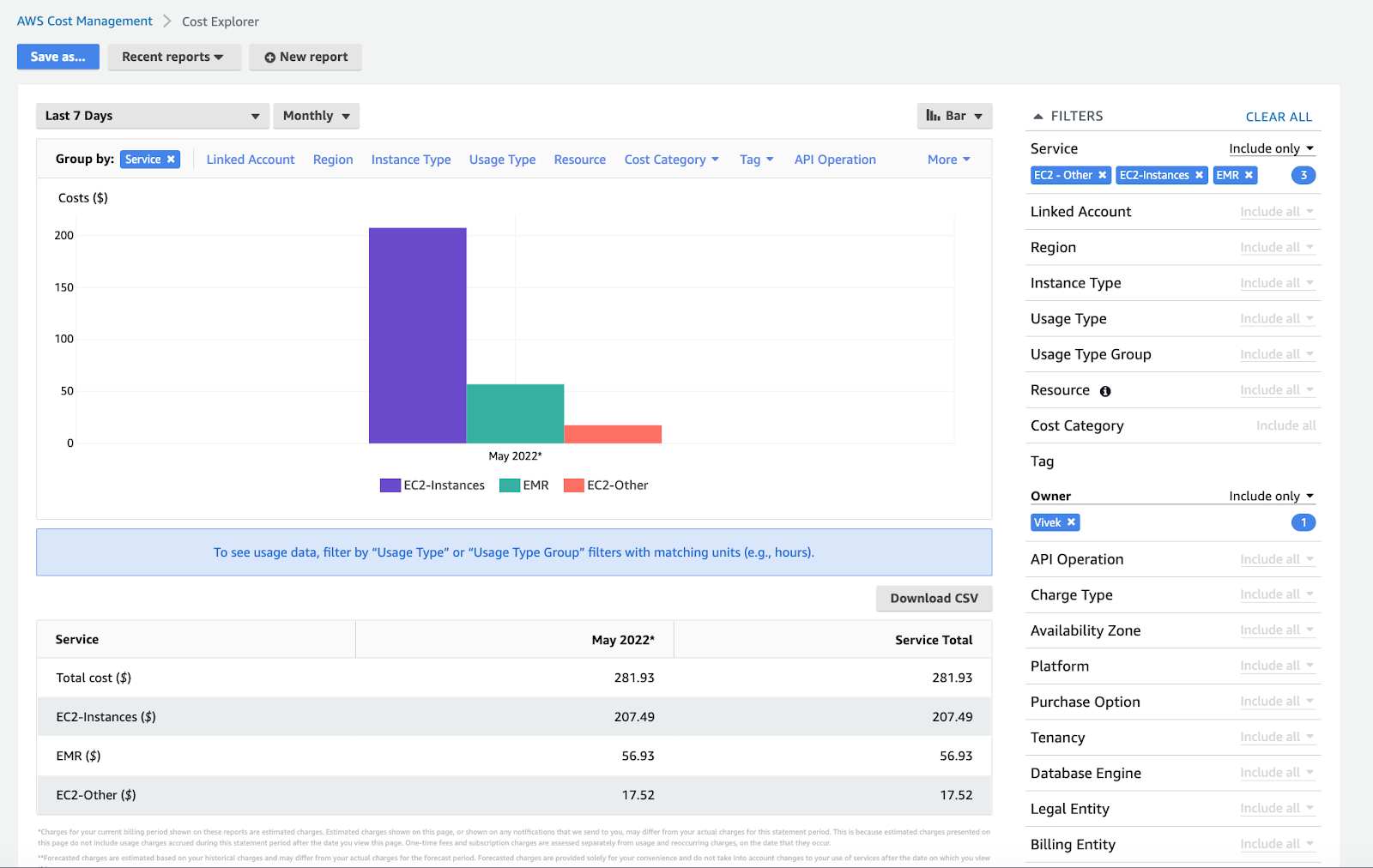
To manage and meet your costs within your budget, you need to diligently monitor your costs. One tool that AWS offers you here is AWS Cost Explorer, which allows you to visualize, understand, and manage your AWS costs and usage over time.
With Cost Explorer, you can build custom applications to directly access and query your costs and usage data, build interactive and ad-hoc analytics reports over a daily or monthly granularity. You can even create a forecast by selecting a future time range for your reports, estimate your AWS bill and set alarms and budgets based on predictions.
Unravel can help!
Without doubt, AWS helps you manage your EMR clusters and its costs with the above listed pathways. And, Cost Explorer is a great tool to use for monitoring your monthly bill, however, that all does come with a price where you have to spent your precious time checking and monitoring things manually or writing custom scripts to fetch the data and then run that data by your data science teams and finance ops for detailed analysis.
Further, the data provided by the Cost Explorer for your EMR cluster costs is not in real-time (has a turn around of 24 hours delay). And, it is also difficult to access your EMR cluster cost usage with other services costs included. However, not to worry, there is a better solution available today — a dataops observability product from the company Unravel Data! — which frees you completely from worrying all about your EMR cluster management and costs as it gives you the real-time view, holistic and fully automated way to manage your clusters!
AWS EMR Cost Management is made easy with Unravel Data
Although there are many tools offered by AWS as well other companies to manage your EMR cluster costs, Unravel stands out with its key offerings of providing you a single pane of glass and ease of use.
Unravel provides an automated observability for your modern data stack!
Unravel’s purpose-built observability for modern data stacks helps you stop firefighting issues, control costs, and run faster data pipelines, all monitored and observed via a single pane of glass.
One unique value that Unravel provides is Chargeback details for the EMR clusters in real-time, where a detailed cost breakdown is provided for your services (EMR, EC2, and EBS volumes) for each configured AWS account. In addition, you get a holistic view of your cluster with respect to resources utilization, chargeback and instance health, with automated Artificial Intelligence based delivered cluster cost-saving recommendations and suggestions.
AWS EMR Monitoring with Unravel’s DataOps Observability
Unravel 4.7.4 has the capability to holistically monitor your EMR cluster. It collects and monitors a range of data points for various KPIs and metrics, with which it then builds a knowledge base to derive the resource and cost saving insights and recommendation decisions.
AWS EMR chargeback and showback
The image below shows the cost breakdown for EMR, EC2 and EBS services

Monitoring AWS EMR cost trends
For your EMR cluster usage, it is important to see how the costs are trending based on your usage and workload size. Unravel helps you with understanding your costs via its chargeback page. Our agents are constantly fetching all the relevant metrics used for analyzing the cluster costs usage and resource utilization, showing you the instant chargeback view in real-time. These collected metrics are further feeded into our AI engine to give you the recommended insights.
The image below shows the cost trends per cluster type, avg costs and total costs

Complete monitoring AWS EMR insights

As seen in the above image, Unravel has analyzed the resources utilization (both memory and CPU) of the clusters and analyzed the configured instance types used for your cluster. Further, based on your executed workload size, Unravel has come up with a set of recommendations to help you save costs by downsizing your node instance types.
Do you want to lower your AWS EMR cost?
Avoid overspending on AWS EMR. If you’re not sure how to lower your AWS EMR cost, or simply don’t have time, the Unravel’s DataOps Observability tool can help you save cost.
Get a free health check.
Schedule a free consultation.
Watch video: 5 Best Practices for Optimizing Your Big Data Costs With Amazon EMR
References
Amazon EMR | AWS Tags | Amazon EC2 instance Types | AWS Cost Explorer | Unravel | Unravel EMR Chargeback | Unravel EMR Insights