

Self-Service Big Data Analytics is the key to enabling a data driven organization. Enterprises understand the value of this capability and are investing heavily in technology, tools, processes and people to make this a reality. However, as rightfully pointed out by the recent Gartner report on big data self service analytics and BI, several challenges remain. While I agree with many of the assessments from Gartner, I also view that there are some key requirements enabling a self-serve analytics paradigm:
1. (Self-Serve) Platform & Infrastructure
We need modern Data Management platforms to be agile to address the self-serve needs. We are headed towards a model of “Query-As-a-Service” where end users expect the right infrastructure and analytic frameworks (batch, real-time, streaming etc.) provisioned appropriately to support their analytic needs, regardless of scale and complexity.
2. Security/Governance
Modern data stack platforms are democratizing access to data. We now have the capability to store all of the data in a single scalable platform and make it accessible for a wide range of analysis. This presents both an opportunity and challenge. Enterprises need to ensure that they have the right “controls” and “governance” structures in place, so only the right data is accessible for the right analysis and relevant users.
3. Self-Service Application Performance Management
While this is often an afterthought, end-users should have an easy way to understand and rationalize the performance of their analytic applications and in many cases also be able to optimize them for the desired SLA. In the absence of this “layer”, end users spend a lot of time depending on their IT organization to do these tasks for them or jump through hoops to get the appropriate information (logs, metrics, configuration data) to understand their application performance. This approach slow down or defeats the whole self-service approach!
At Unravel, we are squarely focused on solving the Self-Service Application Performance Management (APM) challenges for modern analytic applications built on modern data stack platforms. Unravel is built ground-up to provide a complete 360 degree view of applications and provide insights and recommendation on what needs to be done to improve performance and address failures associated with these applications – all in a self-serve fashion.
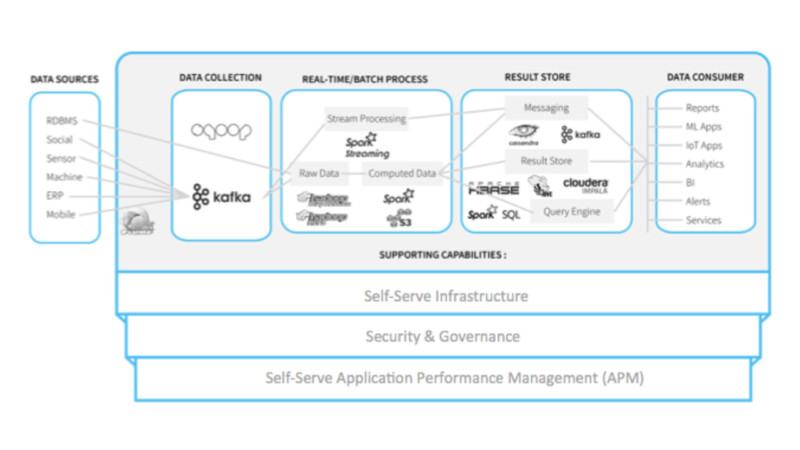
Unravel deployment is streamlined to integrate easily with a self-serve platform/infrastructure and integrates with existing security layers both at the infrastructure level (e.g kerberos) and platform level (e.g Apache Sentry, Apache Ranger etc.). Another unique capability in Unravel is to provide a role-based access control (RBAC) for users. This feature enables end users to view only their applications or those related to their business organization (mapped to a queue, project, tenant, departments etc.).
You can learn more about how Unravel can enable your organization achieve the self-serve analytics paradigm by visiting us at www.unraveldata.com or meeting us at the Strata San Jose 2018 Conference at booth #1329