

Most organizations spend at least 37% (sometimes over 50%) more than they need to on their cloud data workloads. A lot of costs are incurred down at the individual job level, and this is usually where there’s the biggest chunk of overspending. Two of the biggest culprits are oversized resources and inefficient code. But for an organization running 10,000s or 100,000s of jobs, finding and fixing bad code or right-sizing resources is shoveling sand against the tide. Too many jobs taking too much time and too much expertise. That’s why more and more organizations are progressing to the next logical step, to DataFinOps, and leveraging observability, automation, and AI to find–and ideally, fix–all those thousands of places where costs could and should be optimized. This is the stuff that without AI takes even experts hours or days (even weeks) to figure out. In a nutshell, DataFinOps empowers “self-service” optimization, where AI does the heavy lifting to show people exactly what they need to do to get cost right from the get-go.
DataFinOps and job-level “spending decisions”
One of the highly effective core principles of DataFinOps–the overlap and marriage between DataOps and FinOps–is the idea of holding every individual accountable for their own cloud usage and cost. Essentially, shift cost-control responsibility left, to the people who are actually incurring the expenses.
Now that’s a big change. The teams developing and running all the data applications/pipelines are, of course, still on the hook for delivering reliable results on time, every time–but now cost is right up there with performance and quality as a co-equal SLA. But it’s a smart change: let’s get the cost piece right, everywhere, then keep it that way.
At any given time, your organization probably has hundreds of people running 1,000s of individual data jobs in the cloud–building a Spark job, or Kafka, or doing something in dbt or Databricks. And the meter is always ticking, all the time. How high that meter runs depends a lot on thousands of individual data engineering “spending decisions” about how a particular job is set up to run. In our experience with data-forward organizations over the years, as much as 60% of their cost savings were found by optimizing things at the job level.
Enterprises have 100,000s of places where cloud data spending decisions need to be made.
When thinking about optimizing cloud data costs at the job level, what springs to mind immediately is infrastructure. And running oversized/underutilized cloud resources is a big problem–one that the DataFinOps approach is especially good at tackling. Everything runs on a machine, sooner or later, and data engineers have to make all sorts of decisions about the number, size, type of machine they should request, how much memory to call for, and a slew of other configuration considerations. And every decision carries a price tag.
There’s a ton of opportunity to eliminate inefficiency and waste here. But the folks making these spending decisions are not experts at making these decisions. Very few people are. Even a Fortune 500 enterprise could probably count on one hand the number of experts who can “right-size” all the configuration details accurately. There just aren’t enough of these people to tackle the problem at scale.
But it’s not just “placing the infrastructure order” that drives up the cost of cloud data operations unnecessarily. Bad code costs money, but finding and fixing it takes–again–time and expertise.
So, we have the theory of FinOps kind of hitting a brick wall when it comes into contact with the reality of today’s data estate operations. We want to hold the individual engineers accountable for their cloud usage and spend, but they don’t have the information at their fingertips to be able to use and spend cloud resources wisely.
In fact, “getting engineers to take action on cost optimization” remains the #1 challenge according to the FinOps Foundation’s State of FinOps 2023 survey. But that stat masks just how difficult it is. And to get individuals to make the most cost-effective choices about configuring and running their particular jobs–which is where a lot of the money is being spent–it has to be easy for them to do the right thing. That means showing them what the right thing is. Otherwise, even if they knew exactly what they were looking for, sifting through thousands of logs and cloud vendor billing data is time-sucking toil. They don’t need more charts and graphs that, while showing a lot of useful information, still leave it to you to figure out how to fix things.

That’s where DataFinOps comes in. Combining end-to-end, full-stack observability data (at a granular level), a high degree of automation, and AI capabilities, DataFinOps identifies a wide range of cost control opportunities–based on, say, what resources you have allocated vs. what resources you actually need to run the job successfully–then automatically provides a prescriptive AI-generated recommendation on what, where, how to make things more cost-effective.
Using AI to solve oversized resources and inefficient code at the job level
DataFinOps uses observability, automation, and AI to do a few things. First, it collects all sorts of information that is “hidden in plain sight”–performance metrics, logs, traces, events, and metadata from the dozens of components you have running in your modern data stack, at both the job (Spark, Kafka) and platform (Databricks, Snowflake, BigQuery, Amazon EMR, etc.) level; details from the cloud vendors about what is running, where, and how much it costs; details about the datasets themselves, including lineage and quality–and then stitches it all together into an easily understandable, correlated context. Next, DataFinOps throws some math at all that data to analyze usage and cost, hundreds of AI algorithms and ML models that have been well trained over the years. AI can do this kind of investigation, or detective work, faster and more accurately than humans. Especially at scale, when we’re looking at thousands and thousands of individual spending decisions.
Two areas where AI helps individuals cut to the chase and actually do something about eliminating overspending at the job level–which is where the biggest and longer-term cost savings opportunities can be found–are oversized resources and inefficient code.
Watch now
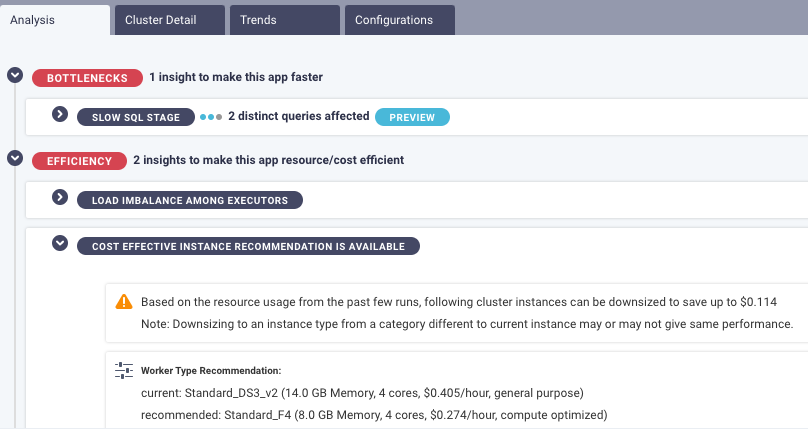
Oversized resources are simply where somebody (or lots of somebodies) requested more resources from the cloud provider than are actually needed to run the job successfully. What DataFinOps AI does is analyze everything that’s running, pinpoint among the thousands of jobs where the number, size, type of resources you’re using is more than you need, calculate the cost implications, and deliver up a prescriptive recommendation (in plain English) for a more cost-effective configuration.
For example, in the screenshot below, the AI has identified more cost-effective infrastructure for this particular job at hand, based on real-time data from your environment. The AI recommendation specifies exactly what type of resource, with exactly how much memory and how many cores, would be less expensive and still get the job done. It’s not quite a self-healing system, but it’s pretty close.
Code problems may be an even more insidious contributor to overspending. Workloads are constantly moving from on-prem Cloudera/Hadoop environments to the cloud. There’s been an explosion of game-changing technologies and platforms. But we’ve kind of created a monster: everybody seems to be using a different system, and it’s often different from the one they used yesterday. Everything’s faster, and there’s more of it. Everybody is trying to do code checks as best they can, but the volume and velocity of today’s data applications/pipelines make it a losing battle.
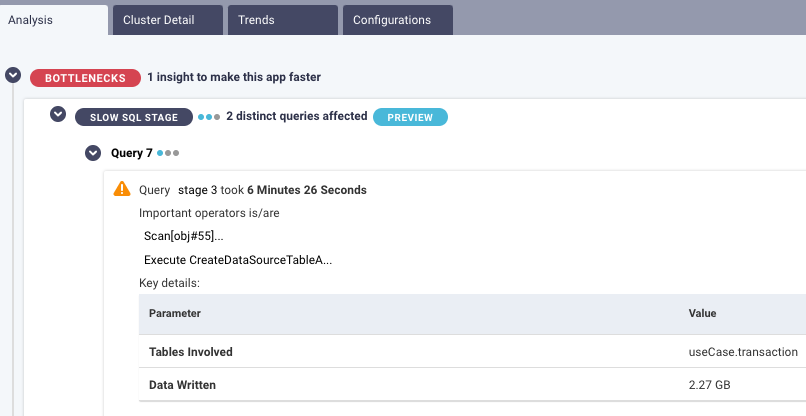
DataFinOps pinpoints where in all that code there are problems causing cloud costs to rise unnecessarily. The ML model recognizes anti-patterns in the code–it’s learned from millions of jobs just like this one–and flags the issue.
In the example below, there’s a slow SQL stage: Query 7 took almost 6½ minutes. The AI/ML has identified this as taking too long, an anomaly or at least something that needs to be corrected. It performs an automated root cause analysis to point directly to what in the code needs to be optimized.
Every company that’s running cloud data workloads is already trying to crack this nut of how to empower individual data engineers with this kind of “self-service” ability to optimize for costs themselves. It’s their spending decisions here at the job level that have such a big impact on overall cloud data costs. But you have to have all the data, and you have to have a lot of automation and AI to make self-service both easy and impactful.
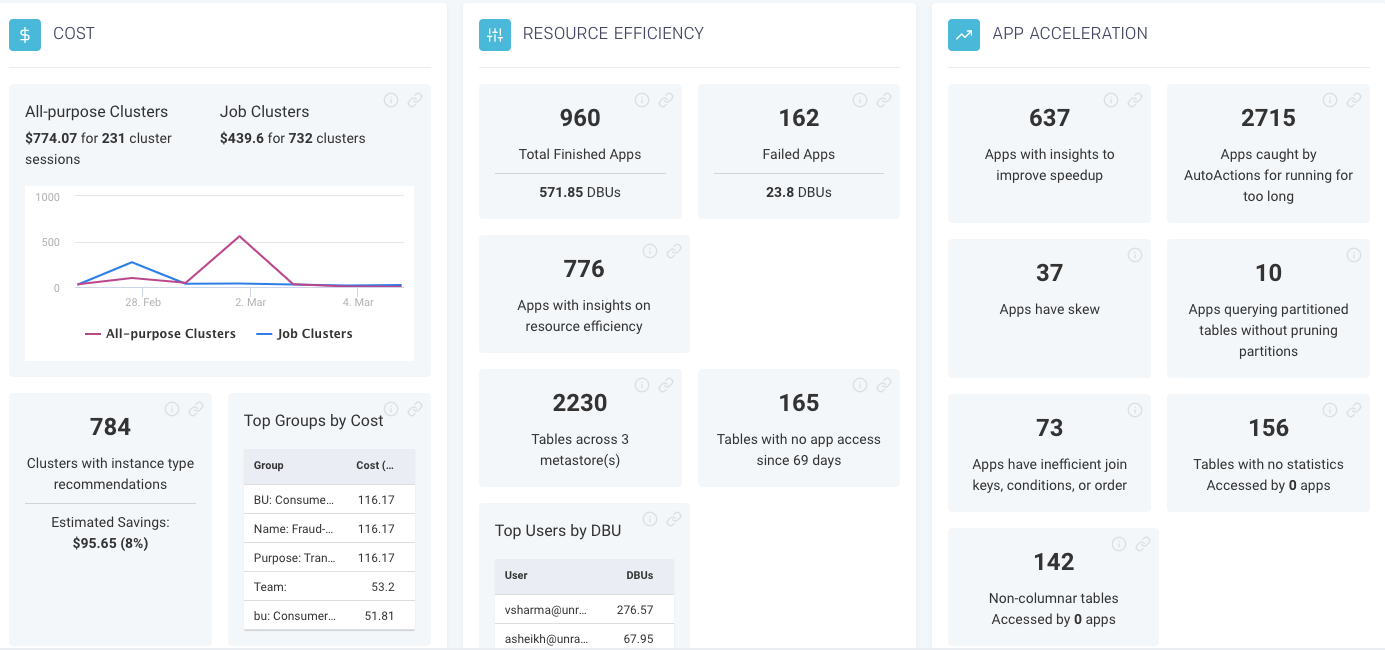
AI recommendations show the individual engineers what to do, so being held accountable for cloud usage and cost is no longer the showstopper obstacle. From a wider team perspective, the same information can be rolled up, sliced-and-diced, into a dashboard that gives a clear picture on the overall state of cost optimization opportunities. You can see how you’re doing (and what still needs to be done) with controlling costs at the cluster or job or even individual user level.
Bottom line: The best way to control cloud data costs in a meaningful way, at scale and speed, with real and lasting impact, is the DataFinOps approach of full-stack observability, automation, and AI.