

Table of Contents
The exponential adoption of IT technologies over the past several decades has had a profound impact on organizations of all sizes. Whether it is a small, medium, or large enterprise, the need to create web applications while managing an extensive set of data effectively is high on every CIO’s priority list.
As a result, there has been an ongoing effort to implement better approaches to software development, data analysis, and data management.
The efforts are so pervasive across industries that these approaches have been given names of their own. The approach to better manage software development and delivery is known as DevOps. The end-to-end approach to efficiently and effectively deliver data products – from responses to SQL queries, to data pipelines, to machine learning models and AI-powered insights – is known as DataOps.
DataOps and DevOps are similar in that they both aim to solve the need to scale delivery. The key difference is that DataOps focuses on the flow of data, and the use of data in analytics, rather than on the software development and delivery lifecycle.
There’s also a difference in impact. Strong DataOps practices are vital to the successful development and delivery of AI-powered applications, including machine learning models. AI and ML are powerful areas of innovation, perhaps the most important in decades. DataOps as a discipline is necessary for the successful development and deployment of AI.
To help you gain an understanding of DataOps vs DevOps, it’s helpful to provide an overview of both, discuss their respective goals, and then highlight the key differences between the two.
DataOps Overview
DataOps is sometimes seen as simply making data flows through an organization, and data transformations, work correctly. This misconception that DataOps is just DevOps applied to data analytics is common. Rather, DataOps is actually a holistic approach to solving business problems.
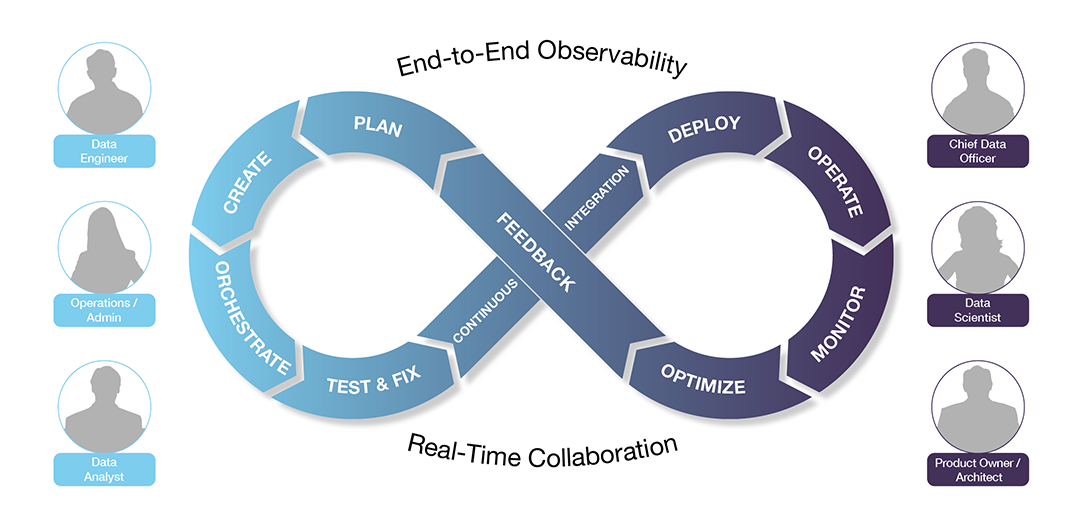
DataOps is a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models and related artifacts. DataOps uses technology to automate the design, deployment and management of data delivery with appropriate levels of governance, and it uses metadata to improve the usability and value of data in a dynamic environment.
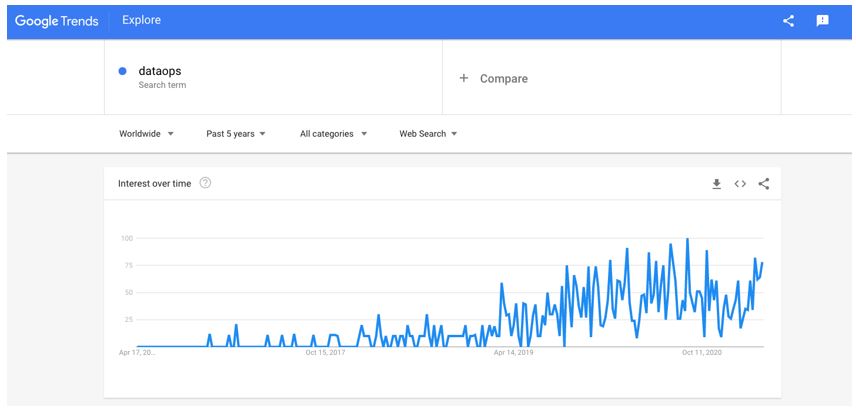
As a concept, DataOps was first introduced by InformationWeek’s Lenny Liebmann in 2014. The term appeared in a blog post on the IBM Big Data & Analytics Hub, titled “3 reasons why DataOps is essential for big data success”.
A few years later, in 2017, DataOps began to get its own ecosystem, dedicated analyst coverage, increased keyword searches, inclusion in surveys, mention in books, and use in open source projects.
DataOps is Not Just Analytics
DataOps is sometimes seen as a set of best practices around analytics. Analytics can be considered to include most of AI and ML, so improving analytics functionality is not a trivial goal. But DataOps is much more than just DevOps applied to analyze data.
Data analytics happens at the end of a data pipeline, while DataOps encompasses nearly a dozen steps, including data ingestion and the entire data pipeline before analytics happens. DataOps also includes the delivery of analytics results and their ultimate business impact. And it serves as a framework for the development and delivery of useful capabilities from AI and ML.
As complex data environments are constantly changing, it is critical for an organization to possess and maintain a solid understanding of their data assets, and to add to their data assets when needed for business success. Understanding the origin of the data, analyzing data dependencies, and keeping documentation up to date are each resource-intensive, yet critical.
Having a high-performing DataOps team in place can help an organization accelerate the DataOps lifecycle – developing powerful, data-centric apps to deliver accurate insights to both internal and external customers.
The Complete Guide to DataOps
DevOps Overview
Now that we’ve briefly described DataOps, let’s discuss DevOps. According to Atlassian, the DevOps movement started to come together between 2007 and 2008. At the time, software development and IT operations communities started raising concerns about an increase in what they felt was a near-fatal level of dysfunction in the industry.
The primary dysfunction these two groups saw was that in a traditional software development model, those who wrote the code were functionally and organizationally separate and apart from those who deployed and supported the code.
As such, software developers and IT Operations teams had competing objectives, different leadership, and different KPIs by which each group was measured and evaluated. As a result, teams were siloed and only concerned with what had a direct impact on them.
The result: poorly executed software releases, unhappy customers, and often unhappy development and IT Operations teams.
Over time, DevOps evolved to solve the pain caused by these siloed teams and poor lines of communication between software developers and IT Operations.
What is DevOps
DevOps describes an approach to software development that accelerates the build lifecycle using automation. By focusing on continuous integration and delivery of software, and by automating the integration, testing, and deployment of code, enterprises start to see many benefits. Specifically, this approach of merging DEVelopment and OPerationS, reduces time to deployment, increases time to market, keeps defects or bugs at a minimum, and generally shortens the time required to resolve any defects.
6 Primary Goals of DevOps
There are six key principles or goals the DevOps aims to deliver.
DevOps Goal 1: Speed
In order to quickly adapt to customer needs, changes in the market, or new business goals, the application development process and release capabilities need to be extremely fast. Practices such as continuous delivery and continuous integration help make it possible to maintain that speed throughout the development and operations phases.
DevOps Goal 2: Reliability
Continuous delivery and integration not only improve the time to market with new code, they also improve the overall stability and reliability of software. Integrating automated testing and exception handling helps software development teams identify problems immediately, minimizing the chances of errors being introduced and exposed to end users.
DevOps Goal 3: Rapid Delivery
DevOps aims to increase the pace and frequency of new software application releases, enabling development teams to improve an application as often as they’d like. Performing frequent, fast-paced releases ensures that the turnaround time for any given bug fix or new feature release is as short as possible.
DevOps Goal 4: Scalability
DevOps focuses on creating applications and infrastructure platforms that quickly and easily scale to address the constantly changing needs and demands of both business needs and end users. A practice that is gaining in popularity that helps scale applications is infrastructure as code, which is the process of managing and provisioning hardware data centers to immediately add resources and capacity for an application.
DevOps Goal 5: Security
DevOps encourages strong security practices by automating compliance policies. This simplifies the configuration process and introduces detailed security controls. This programmatic approach ensures that any resources that fall out of compliance are noticed immediately so they can be evaluated by the development team, in order to get them back into compliance immediately.
DevOps Goal 6: Collaboration
Just like other agile-based software development methodologies, DevOps strongly encourages collaboration throughout the entire software development life cycle. This leads to software development teams that are up to 25% more productive and 50% faster to market than non-agile teams.
Differences between DataOps and DevOps
As outlined above, DevOps is the transformation in the ability and capability of software development teams to continuously deliver and integrate their code.
DataOps focuses on the transformation of intelligence systems and analytic models by data analysts and data engineers.
DevOps brings software development teams and IT operations together with the primary goal to reduce the cost and time spent on the development and release cycle.
DataOps goes one step further, integrating data so that data teams can acquire the data, transform it, model it, and obtain insights that are highly actionable.
DataOps is not limited to making existing data pipelines work effectively, getting reports and Artificial Intelligence and Machine Learning outputs and inputs to appear as needed, and so on. DataOps actually includes all parts of the data management lifecycle.
DataOps, DevOps, and Competitive Advantage
DevOps, as a term and as a practice, grew rapidly in interest and activity throughout the last decade, but has plateaued recently. A decade ago, or even five years ago, aggressive adoption of DevOps as a practice could give an organization a significant competitive advantage. But DevOps is now “table stakes” for modern software development and delivery.
It’s now DataOps that’s in a phase of rapid growth. A big part of the reason for this is the need for strong DataOps practices in developing, and delivering value from, AI and ML. For IT practitioners and management, there are new skills to learn, new ways to deliver value, and in a sense, whole new worlds to conquer, all based on the development, growth, and institutionalization of new practices around data.
At the organizational level, DataOps gives companies the opportunity to innovate, to better serve customers, and to gain competitive advantage by rapid, effective adoption and innovation around DataOps as a practice.
Many of today’s largest and fastest-growing companies are DataOps innovators. Facebook, Apple, Alphabet, Netflix, and Uber are just the best-known among companies which have grown to a previously unheard-of degree, largely based on their innovative (and, often, controversial) practices around the use of data.
Adobe is an example of a company that has grown rapidly – increasing its market value by 4x in the last few years – by adding a data-driven business, the marketing-centered Experience Cloud, to their previously existing portfolio.
Algorithms are hard to protect, competitively, while a company’s data is its own. And, while AI algorithms and machine learning models that depend on this data can be shared, they don’t mean much without the flow of data that powers them. So all this means that innovation based on a company’s data, accelerated by the adoption and implementation of DataOps, is more able to yield lasting and protectable competitive advantage, and contribute to a company’s growth.
Test-drive Unravel for DataOps
Conclusion
It’s fair to say that “DataOps is the new DevOps” – not because one replaces the other, but because DataOps is the hot new area for innovation and competitive advantage. The main difference is that it’s easier for competitive advantage based on data, and on making the best possible use of that data via DataOps, to be enduring.
Unravel Data customers are more easily able to work all steps in the DataOps cycle, because they can see and work with their data-driven applications holistically and effectively. If you’re interested in assessing Unravel for your own data-driven applications, you can create a free account or contact us to learn how we can help.