

How do you monitor, optimize, and really operationalize the data pipeline architecture and workflows in your modern data stack? There are different types of problems that occur every day when you’re running these workflows at scale. How do you go about resolving those common issues?
Understanding Data Pipeline Architecture
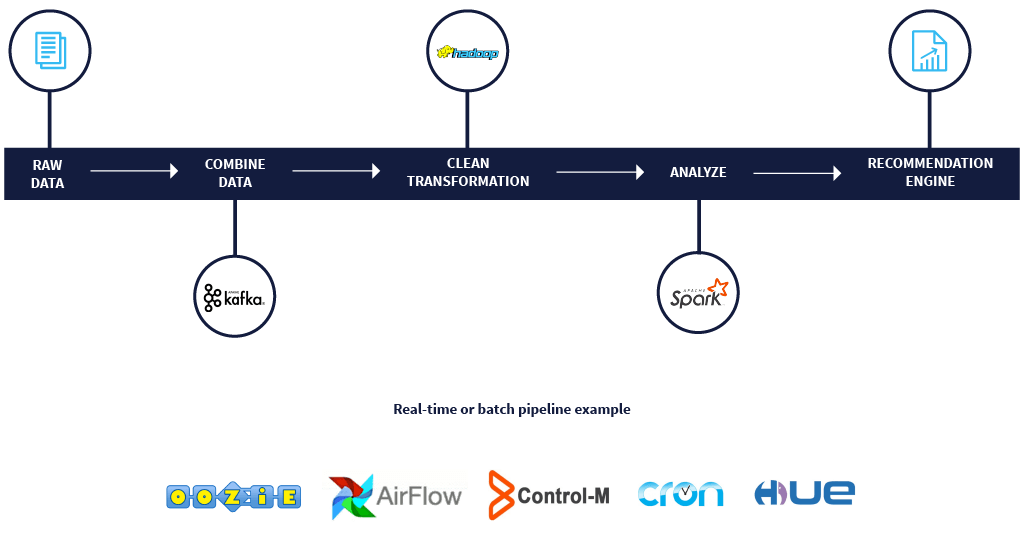
First, let’s quickly understand what we mean by a data pipeline architecture or a workflow. A data pipeline and a workflow are interchangeable terms, and they are comprised of several stages that are stitched together to drive a recommendation engine, a report, a dashboard, etc. These data pipelines or workflows may then be scheduled on top of Oozie or AirFlow or BMC, etc., and may be running repeatedly maybe once every day, or several times during the day.
For example, if I’m trying to create a recommendation engine, I may have all of my raw data in separate files, separate tables, separate systems, that I may put together using Kafka, and then I may load this data into HDFS or S3, after which I’m doing some cleaning and transformation jobs on top of it, merging these data sets together, trying to create a single table out of this, or just trying to clean it up and make sure that all the data’s consistent across these different tables. And then I may run a couple of Spark applications on top, to create my model or analyze this data to create some reports and views. This end-to-end process is an example of a data pipeline or workflow.
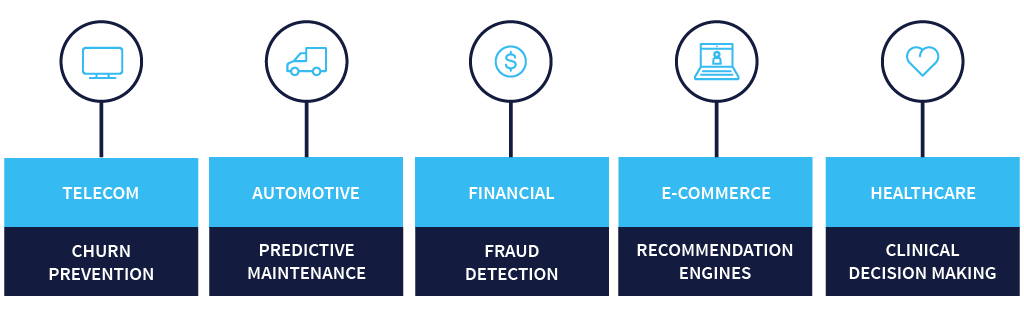
A lot of industries are already running data pipelines and workflows in production. In the telecom industry, we see a lot of companies using these pipelines for churn prevention. In the automotive industry, a lot of companies are using data pipeline architecture for predictive maintenance using IoT applications. For instance, datasets could be going in through Kafka in a real-time fashion, and then running some Spark streaming applications to be able to predict any faults or problems that may happen with the entire manufacturing line itself. A financial services company may be using this for fraud detection with your credit card. Additional examples of data pipeline architecture include e-commerce companies’ recommendation engines, and healthcare companies improving clinical decision making.
Data Pipeline Architecture Common Problems
Data pipelines are mission critical applications, so getting them to run well, and getting them to run reliably, is very important. However, that’s not usually the case, when we try to create data pipelines and workflows on modern data stack systems there are four common problems that occur every time.
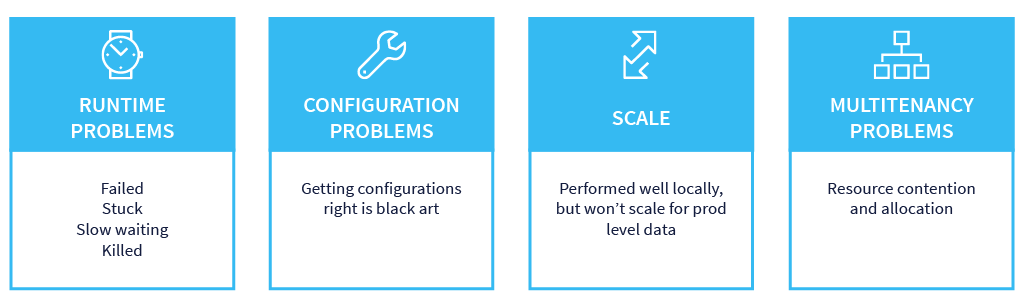
- You may have runtime problems, meaning an application just won’t work.
- You may have configuration settings problems, where are you trying to understand how to set these different configuration setting levels to make these applications run in the most efficient way possible?
- You may have problems with scale, meaning this application ran with 10 GB of data just fine, but what about when it needs to run with 100 GB or PB, will it then still finish in the same amount of time or not?
- You may have multi-tenancy issues where hundreds of possible users, and tens of thousands of applications / jobs / workflows, are all running together in the same cluster. As a result, you may have other applications affecting the performance of your application.
In this blog series, we will look into all these different types of problems in a little more depth and understand, how they can be solved.
COMING SOON



