

Table of Contents
Data teams and their business-side colleagues now expect—and need—more from their observability solutions than ever before. Modern data stacks create new challenges for performance, reliability, data quality, and, increasingly, cost. And the challenges faced by operations engineers are going to be different from those for data analysts, which are different from those people on the business side care about. That’s where DataOps observability comes in.
But what is DataOps observability, exactly? And what does it look like in a practical sense for the day-to-day life of data application developers or data engineers or data team business leaders?
In the Unravel virtual panel discussion What Is Data Observability? Sanjeev Mohan, principal with SanjMo and former Research Vice President at Gartner, lays out the business context and driving forces behind DataOps observability, and Chris Santiago, Unravel Vice President of Solutions Engineering, shows how different roles use the Unravel DataOps observability platform to address performance, cost, and quality challenges.
Why (and what is) DataOps observability?
Sanjeev opens the conversation by discussing the top three driving trends he’s seeing from talking with data-driven organizations, analysts, vendors, and fellow leaders in the data space. Specifically, how current economic headwinds are causing reduced IT spend—except in cloud computing and, in particular, data and analytics. Second, with the explosion of innovative new tools and technologies, companies are having difficulty in finding people who can tie together all of these moving pieces and are looking to simplify this increasing complexity. Finally, more global data privacy regulations are coming into force while data breaches continue unabated. Because of these market forces, Sanjeev says, “We are seeing a huge emphasis on integrating, simplifying, and understanding what happens between a data producer and a data consumer. What happens between these two is data management, but how well we do the data management is what we call DataOps.”
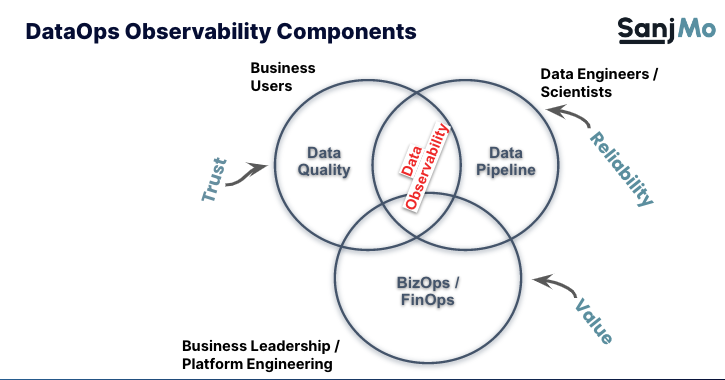
Sanjeev presents his definition of DataOps, why it has matured more slowly than its cousin DevOps, and the kind(s) of observability that is critical to DataOps—data pipeline reliability and trust in data quality—and how his point of view has evolved to now include a third dimension: demonstrating the business value of data through BizOps and FinOps. Taken together, these three aspects (performance, cost, quality) give all the different personas within a data team the observability they need. This is what Unravel calls DataOps observability.
Video on demand
DataOps observability in practice with Unravel
Chris Santiago walks through how the various players on a data team—business leadership, application/pipeline developers and engineers, data analysts—use Unravel across the three critical vectors of DataOps observability: performance (reliability of data applications/pipelines), quality (trust in the data), and cost (value/ROI modern data stack investments).
Cost (value, ROI)
First up is how Unravel DataOps observability provides deep visibility and actionable intelligence into cost governance. As opposed to the kind of dashboards that cloud providers themselves offer—which are batch-processed aggregated summaries—Unravel lets you drill down from that 10,000-foot view into granular details to see exactly where the money is going. Chris uses a Databricks chargeback report example, but it would be similar for Snowflake, EMR, or GCP. He shows how with just a click, you can filter all the information collected by Unravel to see with granular precision which workspaces, teams, projects, even individual users, are consuming how many resources across your entire data estate—in real time.
From there, Chris demonstrates how Unravel can easily set up budget tracking and automated guardrails for, say, a user (or team or project or any other tagging category that makes sense to your particular business). Say you want to track usage by the metric of DBUs; you set the budget/guardrail at a predefined threshold and get real-time status insight into whether that user is on track or is in danger of exceeding the DBU budget. You can set up alerts to get ahead of usage instead of getting notified only after you’ve blown a monthly budget.
See more self-paced interactive product tours here
Performance (reliability)
Chris then showed how Unravel DataOps observability helps the people who are actually on the hook for data pipeline reliability, making sure everything is working as expected. When applications or pipelines fail, it’s a cumbersome task to hunt down and cobble together all the information from disparate systems (Databricks, Airflow, etc.) to understand the root cause and figure out the next steps. Chris shows how Unravel collects and correlates all the granular details about what’s going on and why from a pipeline view. And then how you can drill down into specific Spark jobs. From a single pane of glass, you have all the pertinent logs, errors, metrics, configuration settings, etc., from Airflow or Spark or any other component. All the heavy lifting has been done for you automatically.
But where Unravel stands head and shoulders above everyone else is its AI-powered analysis. Automated root cause analysis diagnoses why jobs failed in seconds, and pinpoints exactly where in a pipeline something went wrong. For a whole class of problems, Unravel goes a step further and provides crisp, prescriptive recommendations for changing configurations or code to improve performance and meet SLAs.
See more self-paced interactive product tours here
Data quality (trust)
Chris then pivots away from the processing side of things to look at observability of the data itself—especially how Unravel provides visibility into the characteristics of data tables and helps prevent bad data from wreaking havoc downstream. From a single view, you can understand how large tables are partitioned, size of the data, who’s using the data tables (and how frequently), and a lot more information. But what may be most valuable is the automated analysis of the data tables. Unravel integrates external data quality checks (starting with the open source Great Expectations) so that if certain expectations are not met—null values, ranges, number of final columns—Unravel flags the failures and can automatically take user-defined actions, like alert the pipeline owner or even kill a job that fails a data quality check. At the very least, Unravel’s lineage capability enables you to track down where the rogue data got introduced and what dependencies are affected.
Video on demand
Whether it’s engineering teams supporting data pipelines, developers themselves making sure they hit their SLAs, budget owners looking to control costs, or business leaders who funded the technology looking to realize full value—everyone who constitutes a “data team”—DataOps observability is crucial to ensuring that data products get delivered reliably on time, every time, in the most cost-efficient manner.
The Q&A session
As anybody who’s ever attended a virtual panel discussion knows, sometimes the Q&A session is a snoozefest, sometimes it’s great. This one is the latter. Some of the questions that Sanjeev and Chris field:
- If I’m migrating to a modern data stack, do I still need DataOps observability, or is it baked in?
- How is DataOps observability different from application observability?
- When should we implement DataOps observability?
- You talked about FinOps and pipeline reliability. What other use cases come up for DataOps observability?
- Does Unravel give us a 360 degree view of all of the tools in the ecosystem, or does it only focus on data warehouses like Snowflake?
To jump directly to the Q&A portion of the event, click on the video image below.