

Table of Contents
Unravel Co-Founder and CTO Shivnath Babu recently hosted an informal roundtable discussion with representatives from Fortune 500 insurance firms, healthcare providers, and other enterprise companies. It was a chance for some peer-to-peer conversation about the challenges of migrating to the cloud and talk shop about Databricks. Here are some of the highlights.
Where are you on your cloud journey?
Everybody is at a different place in their migration to the cloud. So, the first thing we wanted to understand is exactly where each participant stood. While cloud migration challenges are pretty much universally the same for anyone, the specific top-of-mind challenges are a bit different at each stage of the game.
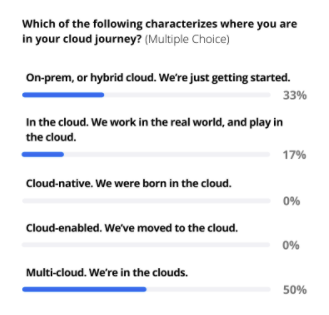
About one-third of the participants said that they are running their data applications on a mix of on-prem and cloud environments. This is not surprising, as most of the attendees work in sectors that have been leveraging big data for some time—specifically, insurance and healthcare—and so have plenty of legacy systems to contend with. As one contributor noted, “If a company has been around for more than 10 years, they are going to have multiple systems and they’re going to have legacy systems. Every company is in some type of digital transformation. They start small with what they can afford. And as they grow, they’re able to buy better products.”
Half indicated that they are in multi-cloud environments—which presents a different set of challenges. One participant who has been on the cloud migration path for 3-4 years said that along the way, “we’ve accumulated new tech debt because we have both AWS Lake Formation and Databricks. This generated some complexity, having two flavors of data catalog. So we’re trying to figure out how to deal with that and get things back on track so we can have better governance over data access.”
What are your biggest challenges in migrating to Databricks?
We polled the participants on what their primary goals are in moving to the cloud and what the top challenges they are experiencing. The responses showed a dead heat (43% each) between “better cost governance, chargeback & forecasting” and “improve performance of critical data pipelines with SLAs,” with “reduce the number of tickets and time to resolution” coming in third.
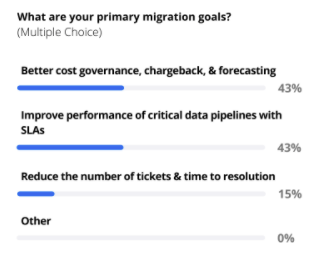
Again, not surprising results given that the majority of the audience were data engineers on the hook for ensuring data application performance and/or people who have been running data pipelines in the cloud for a while. It’s usually not until you start running more and more data jobs in the cloud that cost becomes a big headache.
How does Unravel help with your Databricks environment?
Within the context of the poll questions, Shivnath addressed—at a very high level—how Unravel helps solve the roundtable’s most pressing challenges.
If you think about an entire data pipeline converting data into insights, it can be a multi-system operation: data gets ingested by maybe Kafka, getting into a data lake or lakehouse, but then the actual processing may happen in Databricks. It’s not uncommon to see a dozen or more different technologies among the various components of a modern data pipeline.
What happens quickly is that you end up with an architecture that is very modern, very agile, very cloud-friendly, very elastic but where it’s very difficult to even understand who’s using what and how many resources it takes. An enterprise may have hundreds of data users, with more constantly being added.
Data gets to be like a drug, where the company wants more and more of it, driving more and more insights. And when you compare the number of engineers tasked with fixing problems with the number of data users, it’s clear that there just isn’t enough operational muscle (or enough people with the operational know-how and skill sets) to tackle the challenges.
Stop wasting Databricks spend—act now with a free health check.
Unravel helps fill that gap, and it solves the problem with AI and ML. In a nutshell, what Unravel does is collect all the telemetry information from every system—legacy, cloud, SQL, data pipelines, access to data, the infrastructure—and stream it into the Unravel platform, where it is analyzed with AI/ML to convert that telemetry data into insights to answer questions like
- Where are all my costs going?
- Are they being efficiently used?
- And if not, how do I improve?
Shivnath pointed out that he sees a lot of customers running very large Databricks clusters when they don’t need to. Maybe they’re over-provisioning jobs because of an inefficiency in how the data is stored, or in how the SQL is actually written. Unravel helps with this kind of tuning optimization, reducing costs and building better governance policies from the get-go—so applications are already optimized when they are pushed into production.
Unravel helps different members of data teams. It serves the data operations folks, the SREs, the architects who are responsible for designing the right architecture and setting governance policies, the data engineers who are creating the applications.
And everything is based on applying AI/ML to telemetry data.
Want to see Unravel AI in action? You can get a free health check report to unlock your data environment or contact us.
Other Useful Links
- Our Databricks Optimization Platform
- Get a Free Databricks Health Check
- Check out other Databricks Resources