

Learn more about Apache Spark drivers and how to tune spark application quickly.
During the lifespan of a Spark application, the driver should distribute most of the work to the executors, instead of doing the work itself. This is one of the advantages of using python with Spark over Pandas. The Contented Driver event is detected when a Spark application spends way more time on the driver than the time spent in the Spark jobs on the executors. Leaving the executors idle could waste lots of time and money, specifically in the Cloud environment.
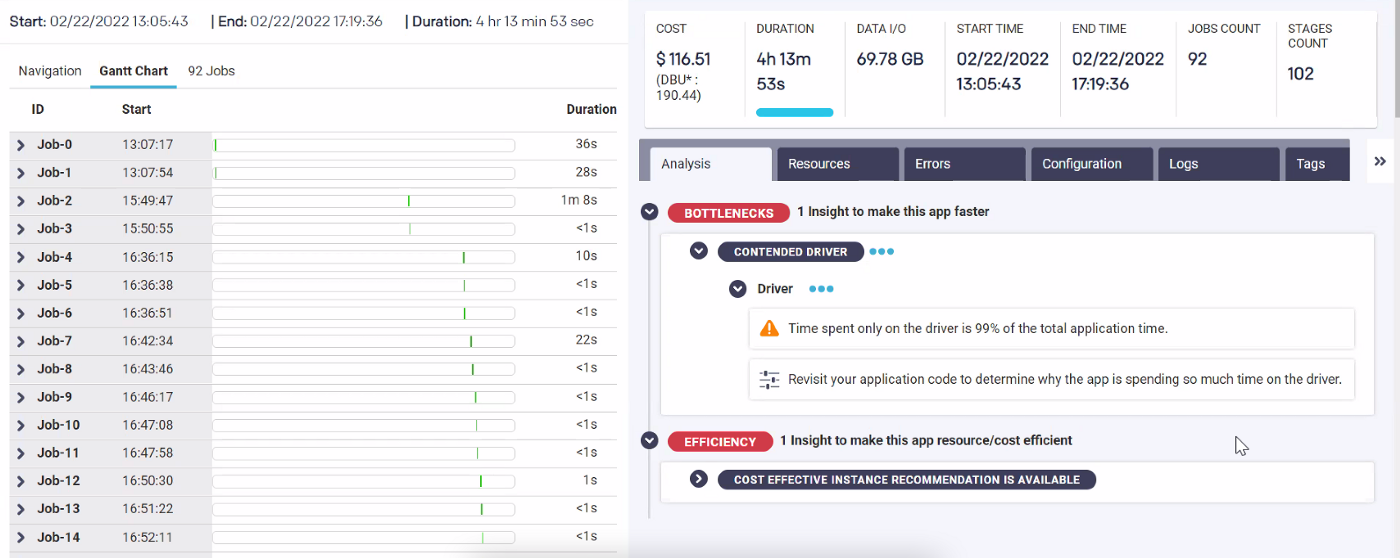
Here is a sample application shown in Unravel for Azure Databricks. Note in the Gantt Chart there was a huge gap of about 2 hours 40 minutes between Job-1 and Job-2, and the job duration for most of the Spark jobs was under 1 minute. Based on the data Unravel collected, Unravel detected the bottleneck which was the contended driver event.
Further digging into the Python code itself, we found that it actually tried to ingest data from the MongoDB server on the driver node alone. This left all the executors idle while the meter was still ticking.
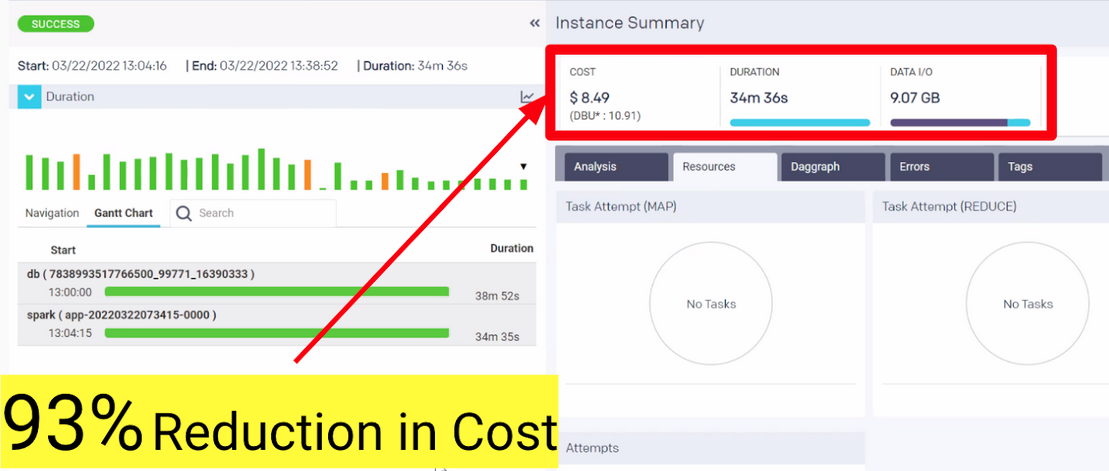
There was some network issue that caused the MongoDB injection slowing down from 15 minutes to 2 plus hours. Once this issue was resolved, there was about 93% reduction in cost. The alternative solution is to move the MongoDB ingestion out of the Spark application. If there is no dependency on previous Spark jobs, we can do it before the Spark application.
If there is a dependency, we can split the Spark application into two. Unravel also collects all the job run status such as Duration and IO as shown below and we can easily see the history of all the job runs and monitor the job.
In conclusion, we must pay attention to the Contended Driver event in a Spark application, so we can save money and time without leaving the executors IDLE for a long time.
Next steps
- Check out what are the biggest spark troubleshooting challenges in 2022 and how to fix them.
- Learn ways to troubleshoot Apache Spark issues.
- Create your free account today.
- Book a demo to see how Unravel simplifies modern data stack management.