

The data landscape is constantly evolving, and with it come new challenges and opportunities for data teams. While generative AI and large language models (LLMs) seem to be all everyone is talking about, they are just the latest manifestation of a trend that has been evolving over the past several years: organizations tapping into petabyte-scale data volumes and running increasingly massive data pipelines to deliver ever more data analytics projects and AI/ML models.
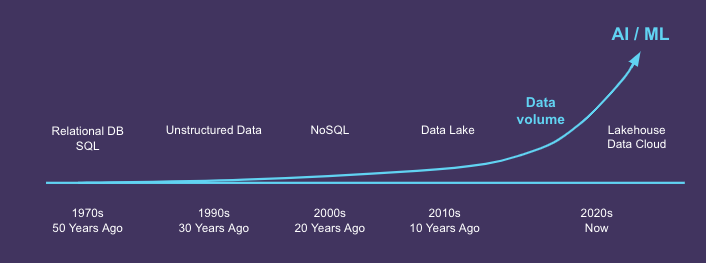
The scale and pace of data consumption is rising exponentially.
Data is now core to every business. Untapping its potential to uncover business insights, drive operational efficiencies, and develop new data products is a key competitive differentiator that separates winners from losers. But running the enormous data workloads that fuel such innovation is expensive. Businesses are already struggling to keep their cloud data costs within budget. So, how can companies increase business-critical data output without sending cloud data costs through the roof?
Effective cost management becomes paramount. That’s where FinOps principles come into play, helping organizations to optimize their cloud resources and align them with business goals.
A recent virtual fireside chat with Sanjeev Mohan, former Gartner Research VP for Big Data & Advanced Analytics and founder/principal of SanjMo, Unravel VP of Solutions Engineering Chris Santiago, and DataOps Champion and Certified FinOps Practitioner Clinton Ford discussed five tips for getting started with FinOps for data workloads.
Why FinOps for Data Makes Sense
The virtual event kicked off discussing Gartner analyst Lydia Leong’s argument that building a dedicated FinOps team is a waste of time. Our panelists broke down why FinOps for data teams is actually crucial for companies running big data workloads in the cloud. Then they talked about how Spotify fixed a $1 million query, using that as an example of FinOps principles in practice.
The experts emphasized that having a clear strategy and plan in place is critical for ensuring that resources are allocated effectively and in line with business objectives.
Five Best Practices for DataFinOps
To set data teams on the path to FinOps success, Sanjeev Mohan and Chris Santiago shared five practical tips during the presentation:
- Discover: Begin by tracking and visualizing your costs at three different layers: the query level, user level, and workload level. You must first know where the money is going, to ensure that resources are properly aligned.
- Understand Cost Drivers: Dig into the top cost drivers—what’s actually incurring the most cost—at a granular level. Not only is this vital for accurately forecasting budgets, but you can prioritize workloads based on their strategic value, ensuring that you’re focusing on tasks that contribute meaningfully to your bottom line.
- Collaborate: FinOps is a team sport among Finance, Engineering, and the business. For many organizations, this is a cultural shift as much as anything. A good start is to leverage chargeback/showback models to hold teams accountable and encourage better management of resources.
- Build Early Warning Systems: Implement guardrails to nip cost overruns in the bud. It’s best to catch performance/cost problems early on in development, whether as part of your CI/CD process or even as simple as triggering an alert when some cost/performance threshold is violated.
- Automate and Optimize: Continuously monitor, automate, and optimize key processes to minimize waste, save time, and achieve better results.
Audience Questions
In addition to discussing FinOps best practices, the panelists fielded several questions from the audience. They addressed topics such as calculating unit costs, selecting impactful visualization tools, and employing cost reduction strategies tailored for their organizations. Throughout the session, the experts emphasized collaboration and partnership, showcasing Unravel’s commitment to empowering data teams to reach their full potential.
The Unravel Advantage
With its AI-powered Insights Engine built specifically for modern data platforms like Databricks, Snowflake, Google Cloud BigQuery, and Amazon EMR, Unravel provides data teams with the performance/cost optimization insights and automation they need to thrive in the competitive data landscape. Just as the recent case study of a leading health insurance provider demonstrated, Unravel’s capabilities are instrumental in helping organizations optimize code and infrastructure to help run more data workloads without increasing their budget. The five FinOps best practices shared by Sanjeev and Chris offer actionable insights for data teams looking to optimize costs, drive efficiency, and achieve their goals in an ever-changing data landscape.
With Unravel as your trusted partner, you can approach FinOps with confidence, knowing that you have access to the expertise, tools, and support required to succeed.
Next Steps
- Schedule a demo with Unravel to discover how it can revolutionize your cost optimization efforts.
- Download Eckerson Group’s Governing Cost with FinOps for Cloud Analytics.