

The benefits of moving your on-prem Spark Hadoop environment to Databricks are undeniable. A recent Forrester Total Economic Impact (TEI) study reveals that deploying Databricks can pay for itself in less than six months, with a 417% ROI from cost savings and increased revenue & productivity over three years. But without the right methodology and tools, such modernization/migration can be a daunting task.
Capgemini’s VP of Analytics Pratim Das recently moderated a webinar with Unravel’s VP of Solutions Engineering Chris Santiago, Databricks’ Migrations Lead (EMEA) Amine Benhamza, and Microsoft’s Analytics Global Black Belt (EMEA) Imre Ruskal to discuss how to reduce the risk of unexpected complexities, avoid roadblocks, and present cost overruns.
The session Optimizing and Migrating Hadoop to Azure Databricks is available on demand, and this post briefly recaps that presentation.
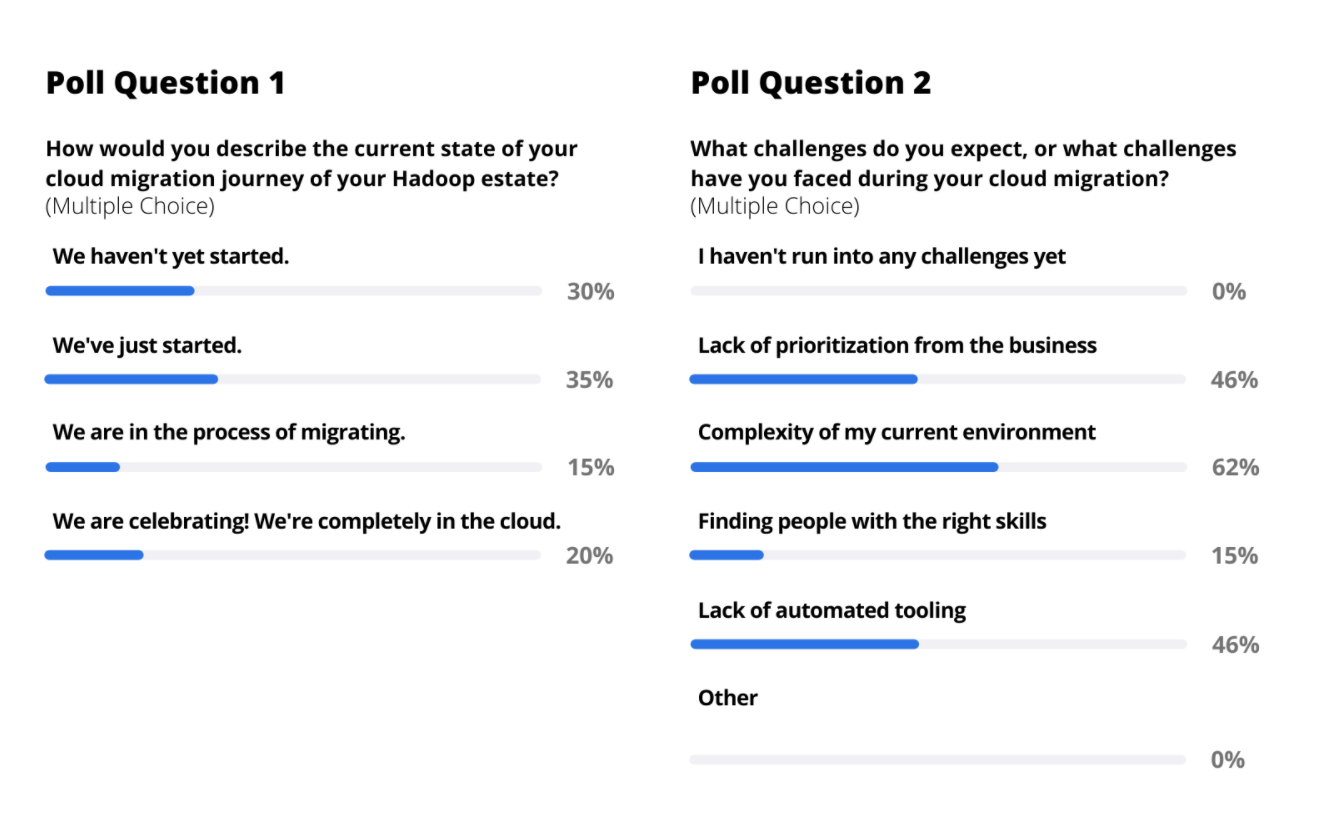
Pratim from Capgemini opened by reviewing the four phases of a cloud migration—assess; plan; test, fix, verify; optimize, manage, scale—and polling the attendees about where they were on their journey and the top challenges they have encountered.
How Unravel helps migrate to Databricks from Hadoop
Chris ran through the stages an enterprise goes through when doing a cloud migration from Hadoop to Databricks (really, any cloud platform), with the different challenges associated with each phase.
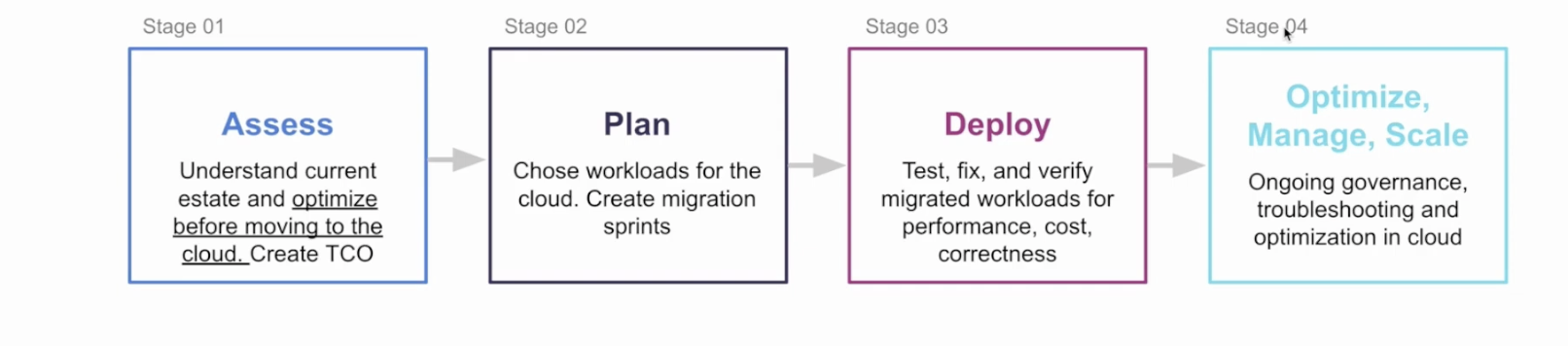
Specifically, profiling exactly what you have running on Hadoop can be a highly manual, time-consuming exercise than can take 4-6 months, requires domain experts, can cost over $500K—and even then is still usually inaccurate and incomplete by 30%.
This leads to problematic planning. Because you don’t have complete data and have missed crucial dependencies, you wind up with inaccurate “guesstimates” that delay migrations by 9-18 months and underestimate TCO by 3-5X
Then once you’ve actually started deploying workloads in the cloud, too often users are frustrated that workloads are running slower than they did on-prem. Manual tuning each job takes about 20 hours in order to meet SLAs, increasing migration expenses by a few million dollars.
Finally, migration is never a one-and-done deal. Managing and optimizing the workloads is a constant exercise, but fragmented tooling leads to cumbersome manual management and lack of governance results in ballooning cloud costs.
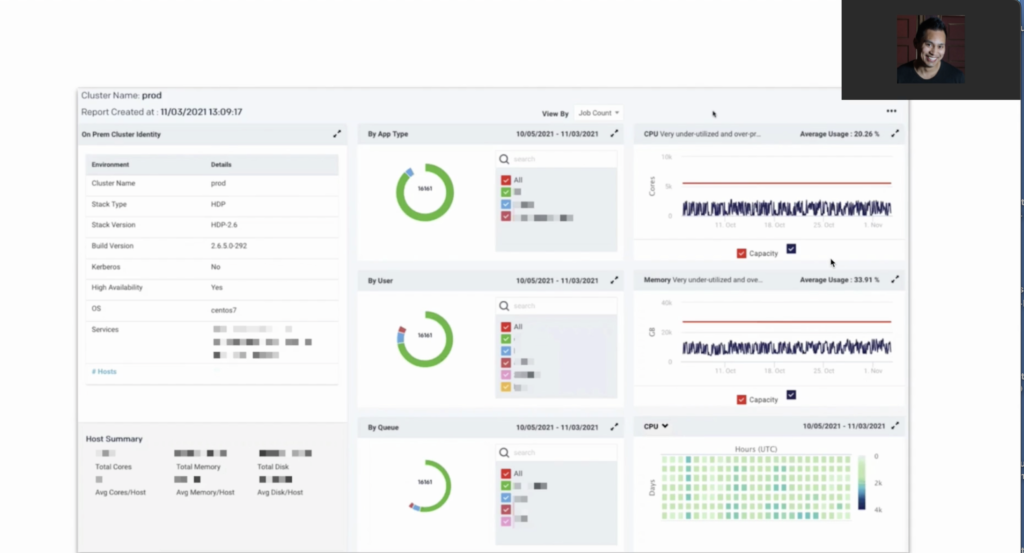
Chris Santiago shows over a dozen screenshots illustrating Unravel capabilities to assess and plan a Databricks migration. Click on image or here to jump to his session.
Chris illustrated how Unravel’s data-driven approach to migrating to Azure Databricks helps alleviate and solve these challenges. Specifically, Unravel answers questions you need to ask to get a complete picture of your Hadoop inventory:
- What jobs are running in your environment—by application, by user, by queue?
- How are your resources actually being utilized over a lifespan of a particular environment?
- What’s the velocity—the number of jobs that are submitted in a particular environment—how much Spark vs. Hive, etc.?
- What pipelines are running (think Airflow, Oozie)?
- Which data tables are actually being used, and how often?
Then once you have a full understanding of what you’re running in the Hadoop environment, you can start forecasting what this would look like in Databricks. Unravel gathers all the information about what resources are actually being used, how many, and when for each job. This allows you to “slice” the cluster to start scoping out what this would look like from an architectural perspective. Unravel takes in all those resource constraints and provides AI-driven recommendations on the appropriate architecture: when and where to use auto-scaling, where spot instances could be leveraged, etc.
Watch webinar
Then when planning, Unravel gives you a full application catalog, both at a summary and drill-down level, of what’s running either as repeated jobs or ad hoc. You also get complexity analysis and data dependency reports so you know what you need to migrate and when in your wave plan. This automated report takes into account the complexity of your jobs, the data level and app level dependencies, and ultimately spits out a sprint plan that gives you the level of effort required.
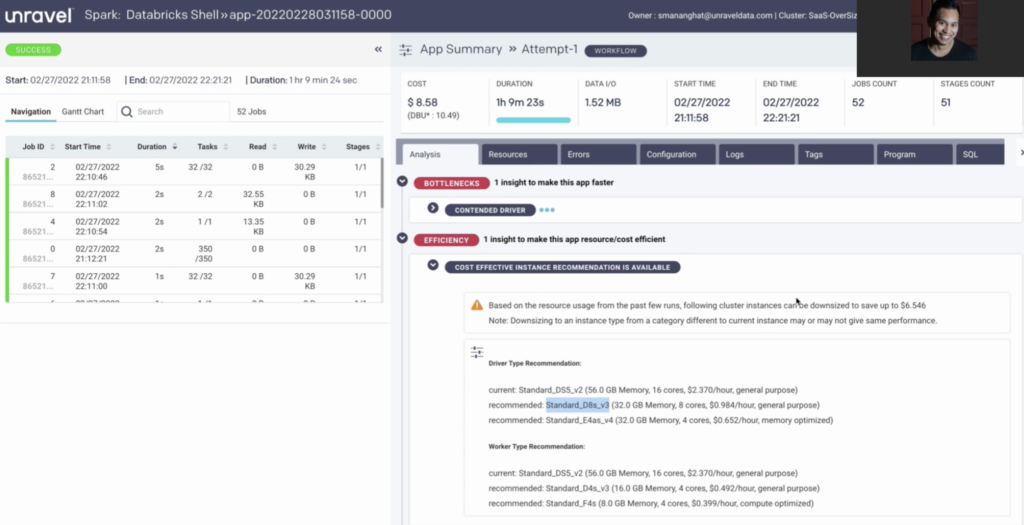
Click on image or here to see Unravel’s AI recommendations in action
But Unravel also helps with monitoring and optimizing your Databricks environment post-deployment to make sure that (a) everyone is using Databricks most effectively and (b) you’re getting the most out of your investment. With Unravel, you get full-stack observability metrics to understand exactly what’s going on with your jobs. But Unravel goes “beyond observability” to not just tell you what’s going and why, but also tell you what to do about it.
By collecting and contextualizing data from a bunch of different sources—logs, Spark UI, Databricks console, APIs—Unravel’s AI engine automatically identifies where jobs could be tuned to run for higher performance or lower cost, with pinpoint recommendations on how to “fix things for greater efficiency. This allows you to tune thousands of jobs on the fly, control costs proactively, and track actual vs. budgeted spend in real time.
Why Databricks?
Amine then presented a concise summary of why he’s seen customers migrate to Databricks from Hadoop, recounting the high costs associated with Hadoop on-prem, the administrative complexity of managing the “zoo of technologies,” the need to decouple compute and storage to reduce waste of unused resources, the need to develop modern AI/ML use cases, not to mention the Cloudera end-of-life issue. He went on to illustrate the advantages and benefits of the Databricks data lakehouse platform, Delta Lake, and how by bringing together the best of Databricks and Azure into a single unified solution, you get a fully modern analytics and AI architecture.
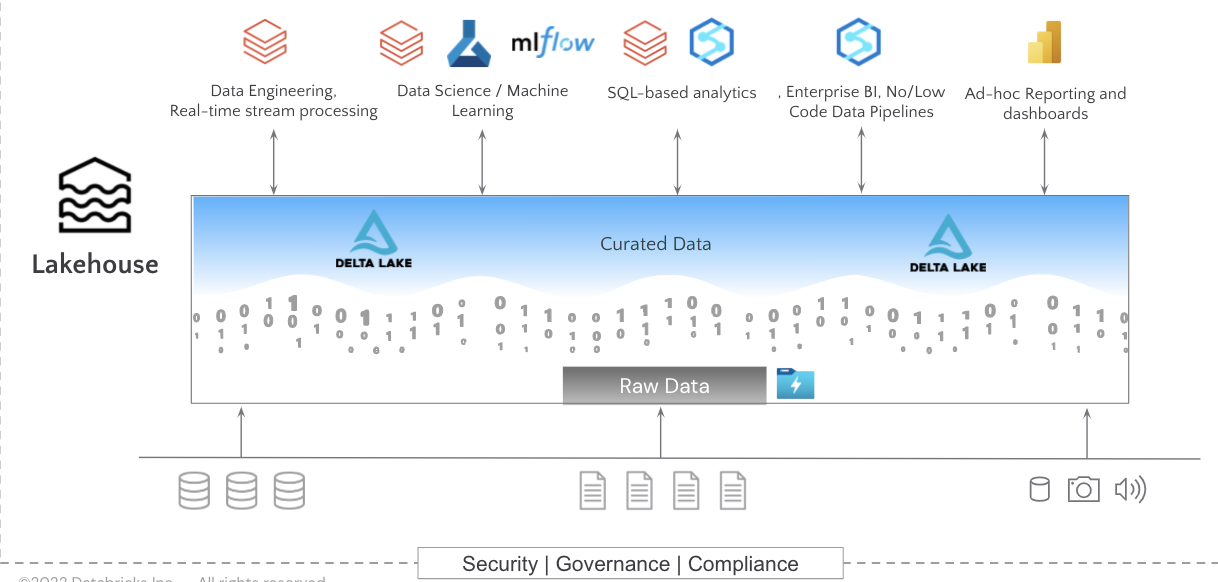
He then went on to show how the kind of data-driven approach that Capgemnini and Unravel take might look for different technologies migrating from Hadoop to Databricks.

Hadoop migration beyond Databricks
The Hadoop ecosystem over time has become extremely complicated and fragmented. If you are looking at all the components that might be in your Hortonworks or Cloudera legacy distribution today, and are trying to map them to the Azure model analytics reference architecture layer, things get pretty complex.
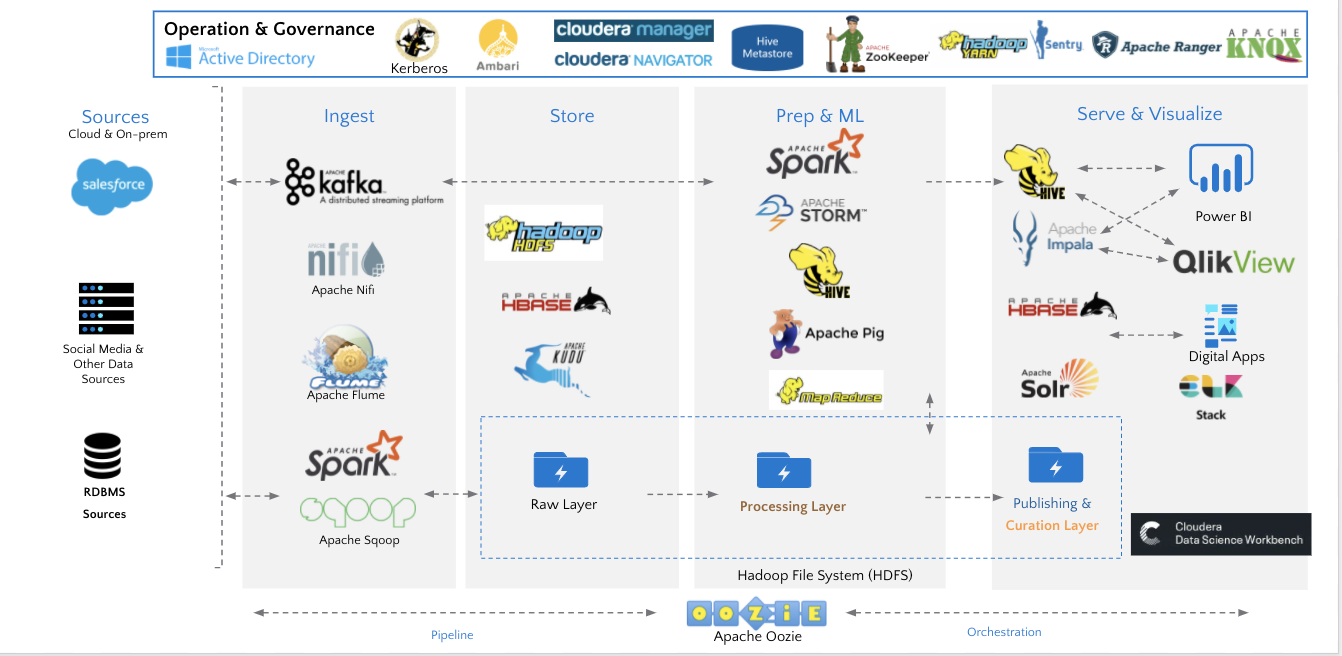
Some things are relatively straightforward to migrate over to Databricks—Spark, HDFS, Hive—others, not so much. This is where his team at Azure Data Services can help out. He went through the considerations and mapping for a range of different components, including:
- Oozie
- Kudi
- Nifi
- Flume
- Kafka
- Storm
- Flink
- Solr
- Pig
- HBase
- MapReduce
- and more
He showed how these various services were used to make sure customers are covered, to fill in the gaps and complement Databricks for an end-to- end solution.
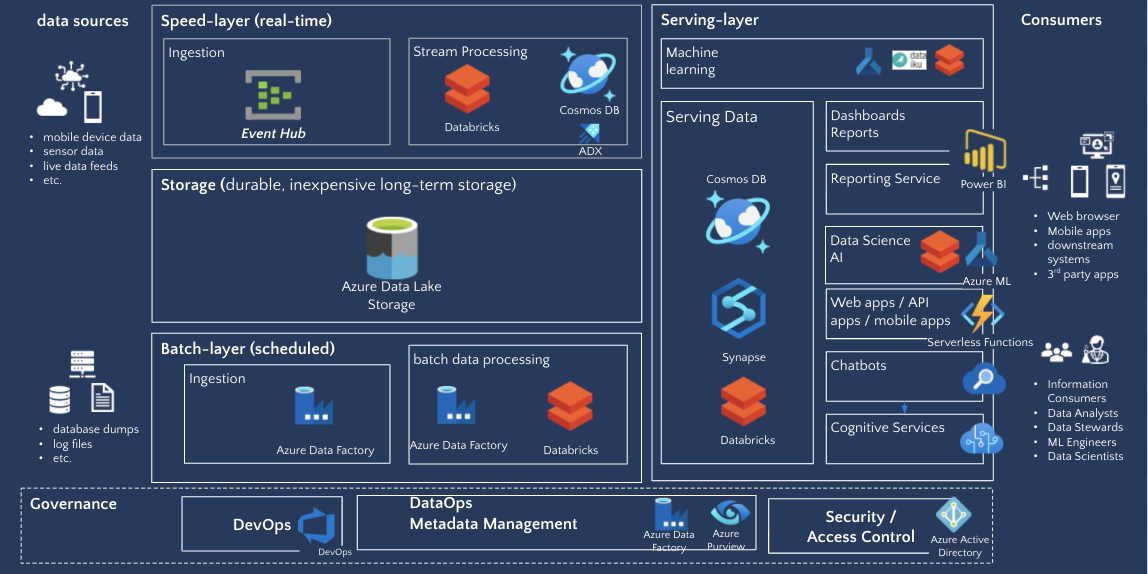
Check out the full webinar Optimizing and Migrating Hadoop to Azure Databricks on demand.
No form to fill out!