

Table of Contents
The term DataOps (like its older cousin, DevOps) means different things to different people. But one thing that everyone agrees on is its objective: accelerate the delivery of data-driven insights to the business quickly and reliably.
As the business now expects—or more accurately, demands—increasingly more insights from data, on increasingly shorter timelines, with increasingly more data being generated, in increasingly more complex data estates, it becomes ever more difficult to keep pace with the new levels of speed and scale.
Eliminating as much manual effort as possible is key. In a recent Database Trends and Applications (DBTA)-hosted roundtable webinar, Succeeding with DataOps: Implementing, Managing, and Scaling, three engineering leaders with practical experience in enterprise-level DataOps present solutions that simplify and accelerate:
- Security. Satori Chief Scientist Ben Herzberg discusses how you can meet data security, privacy, and compliance requirements faster with a single universal approach.
- Analytics. Incorta VP of Product Management Ashwin Warrier shows how you can make more data available to the business faster and more frequently.
- Observability. Unravel VP of Solutions Engineering Chris Santiago explains how AI-enabled full-stack observability accelerates data application/pipeline optimization and troubleshooting, automates cost governance, and delivers the cloud migration intelligence you need before, during, and after your move to the cloud.
 Universal data access and security
Universal data access and security
Businesses today are sitting on a treasure trove of data for analytics. But within that gold mine is a lot of personally identifiable information (PII) that must be safeguarded. That brings up an inherent conflict: making the data available to the company’s data teams in a timely manner without exposing the company to risk. The accelerated volume, velocity, and variety of data operations only makes the challenge greater.
Satori’s Ben Herzberg shared that recently one CISO said he has visibility over his network and his endpoints, but data was like a black box—it was hard for the Security team to understand what was going on. Security policies usually had to be implemented by other teams (data engineering or DataOps, database administrators).
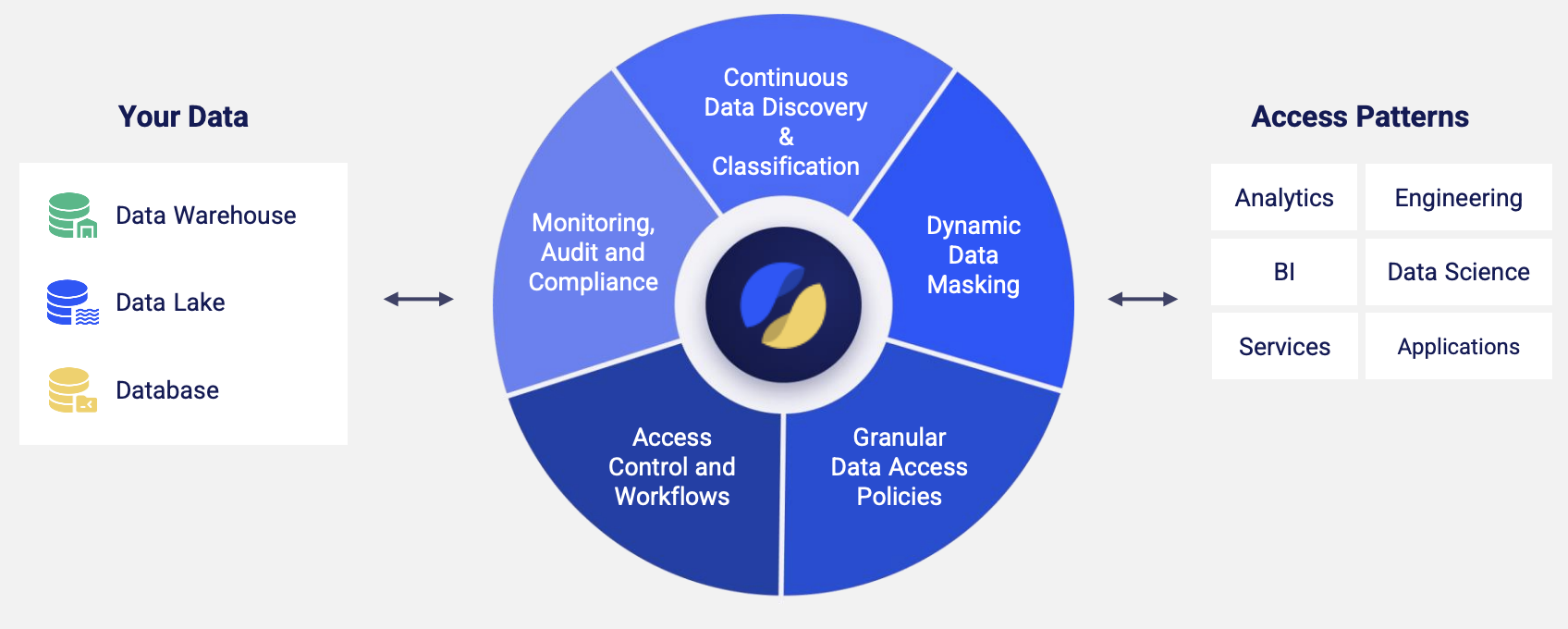
The 5 capabilities of Satori’s DataSecOps
So what Satori does is provide a universal data access and security platform where organizations can manage all their security policies across their entire data environment from one single place in a simplified way. Ben outlined the five capabilities that Satori enables to realize DataSecOps:
- Continuous data discovery and classification
Data keeps on changing, with more people touching it every day. Auditing or mapping your sensitive data once a year, even once a quarter or once a month, may not be sufficient. - Dynamic data masking
Different data consumers need different levels of data anonymization. Usually to dynamically mask data, you have to rely on the different data platforms themselves. - Granular data access policies
A key way to safeguard data is via Attribute-based Access Control (ABAC) policies. For example, you may want data analysts to be able access data stores using Tableau or Looker but not with any other technologies. - Access control and workflows
Satori automates and simplifies the way access is granted or revoked. A common integration is with Slack, so Security team can approve or deny access requests quickly. - Monitoring, audit & compliance Satori sits between the data consumers and the data that’s being accessed, so monitoring/auditing for compliance is transparent without ever touching the data itself.
Keeping data safe is always a top-of-mind concern, but no organization can afford to delay projects for months in order to apply security.
Scaling analytics with DataOps
When you think of the complexity of the modern data stack, you’re looking at a proliferation of cloud-based applications but also many legacy on-prem applications that continue to be the backbone of a large enterprise (SAP, Oracle). You have all these sources rich with operational data that business users need to build analytics on top of. So the first thing you see in a modern data stack is the data being moved to a data lake or data warehouse, to make it readily accessible along with making refinements along the way.
But to Incorta’s Ashwin Warrier, this presents two big challenges when it comes to enterprise analytics and operational reporting. First, getting through this entire process takes weeks, if not months. Second, once you finally get the data into the hands of business users, it’s aggregated. Much of your low-fidelity data is gone because of summarizations and aggregations. Building a bridge between the analytics plane and the operations plane requires some work.
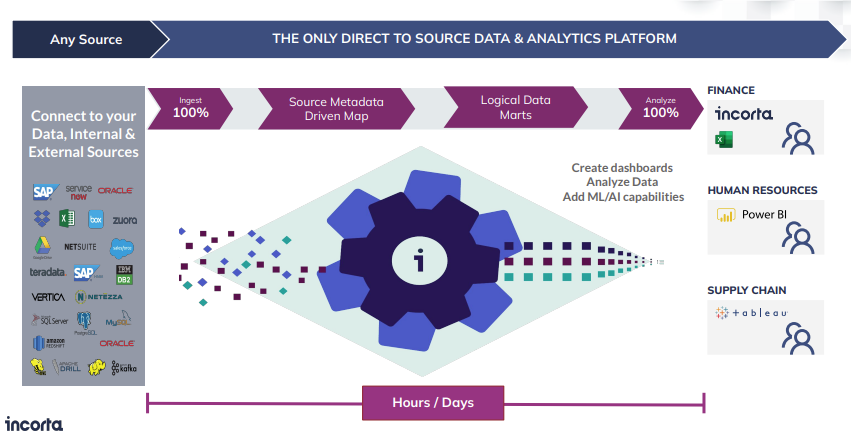
Incorta’s Direct Data Platform approach
Where Incorta is different is that it does enrichments but doesn’t try to create transformations to take your source third normal form data and convert that into star schemas. It takes an exact copy with minimal amount of change. Having the same fidelity means that now your business users can get access to their data at scale in just a matter of hours or days instead of weeks or months.
Ashwin related the example of a Fortune 50 customer with about 2,000 users developing over 5,000 unique reports. It had daily refreshes, with an average query time of over 2 minutes, and took over 8 days to deliver insights. With Incorta, it reduced average query time to just a few seconds, now refreshes data 96 times every day, and can deliver insights in less than 1 day.
Unlock your data environment health with a free health check.
Taming the beast of modern data stacks
Unravel’s Chris Santiago opened with an overview of how the complexity compounded by complexity of modern data stacks causes problems for different groups of data teams. Data engineers’ apps aren’t hitting their SLAs; how can they make them more reliable? Operations teams are getting swamped with tickets; how can they troubleshoot faster? Data architects are falling behind schedule and going over budget; how can they speed migrations without more risk? Business leaders are seeing skyrocketing cloud bills; how can they better govern costs?
Then he went into the challenges of complexity. A single modern data pipeline is complex enough on its own, with dozens or even hundreds of interdependent jobs on different technologies (Kafka, Airflow, Spark, Hive, all the barn animals in Hadoop). But most enterprises run large volumes of these complex pipelines continuously—now we’re talking about the number of jobs getting into the thousands. Plus you’ve got multiple instances and data stored in different geographical locations around the globe. Already it’s a daunting task to figure out where and why something went wrong. And now there’s multi-cloud.
Managing this environment with point tools is going to be a challenge: they are very specific to the service they’re running, and the crucial information you need is spread across dozens of different systems and tools. Chris points out four key reasons why managing modern data stacks with point tools falls flat:

4 ways point tools fall flat for managing the modern data stack
- You get only a partial picture.
The Spark UI, for instance, has granular details about individual jobs but not at the cluster level. Public cloud vendors’ tools have some of this information, but not nothing at the job level. - You don’t get to the root cause.
You’ll get a lot of graphs and charts, but what you really need to know is what went wrong, why—and how to fix it. - You’re blind to where you’re overspending.
You need to know exactly which jobs are using how much resources, whether that’s appropriate for the job at hand, and how you can optimize for performance and cost. - You can’t understand your cloud migration needs.
Things are always changing, and changing fast. You need to always be thinking about the next move.
That’s where Unravel comes in.
Unlock your data environment health with a free health check.
Unravel is purpose-built to collect granular data app/pipeline-specific details from every system in your data estate, correlate it all in a “workload-aware” context automatically, analyze everything for you, and provide actionable insights and precise AI recommendations on what to do next.
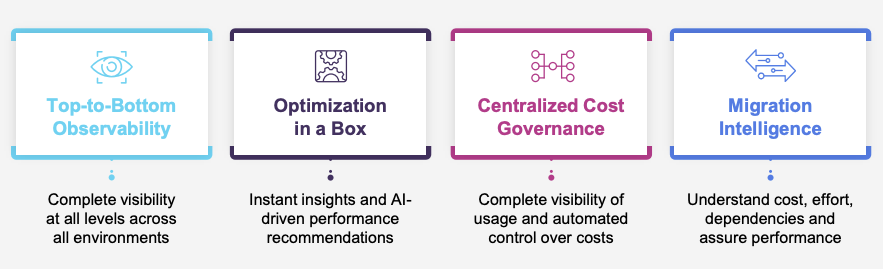
Unravel is purpose-built for the modern data stack
- Get single-pane-of-glass visibility across all environments.
You’ll have complete visibility to understand what’s happening at the job level up to the cluster level. - Optimize automatically.
Unravel’s AI engine is like having a Spark or Databricks or Amazon EMR telling you exactly what you need to do to optimize performance to meet SLAs or change instance configurations to control cloud costs. - Fine-grained insight into cloud costs.
See at a granular level exactly where the money is going, set some budgets, track spend month over month—by project, team, even individual job or user—and have AI uncover opportunities to save. - Migrate on time, on budget.
Move to the cloud with confidence, knowing that you have complete and accurate insight into how long migration will take, the level of effort involved, and what it’ll cost once you migrate.
As businesses become ever more data-driven, build out more modern data stack workloads, and adopt newer cloud technologies, it will become ever more important to be able to see everything in context, let AI take much of the heavy lifting and manual investigation off the shoulders of data teams already stretched too thin, and manage, troubleshoot, and optimize data applications/pipelines at scale.
Check out the full webinar here.