More than a Hadoop apm, Unravel provides unprecedented visibility, monitoring and troubleshooting automation to optimize how that data is used.
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Try for Free
Delivering high performance applications and data monitoring services at Hadoop scale
Unravel for Hadoop provides the context and troubleshooting automation to get maximum performance from data applications that run on the Hadoop ecosystem. Many big data teams continue to rely on Hadoop as the foundation technology for scheduling and running applications, ingesting and persisting data, and managing compute and storage resources. Unravel Hadoop tuning tools provide a new level of observability, monitoring, and understanding of the Hadoop ecosystem and the plain language context to get the most from your data. Get a free health check report to unlock your data environment.
** DO NOT REMOVE Hidden Margin Required **
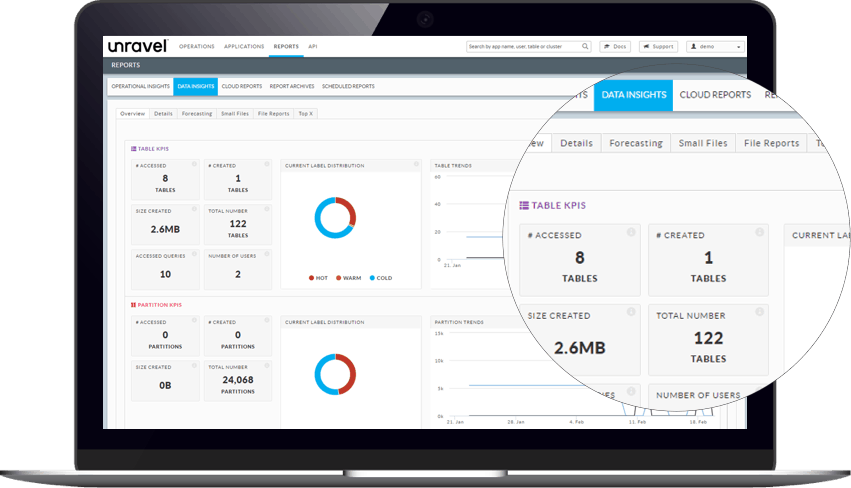
Instant observability of the full Hadoop ecosystem
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Monitoring and understanding the essential elements of a successful implementation
Hadoop is often at the center of data management for large scale data operations and applications in the modern enterprise. It interacts with an ecosystem of Hadoop services and subsystems like Hbase and Hive, as well as adjacent technologies such as Spark, Kafka, and Impala. Unravel provides unprecedented visibility into of the Hadoop ecosystem by:
Natively supporting every leading Hadoop distribution — Cloudera, Hortonworks, MapR, Amazon, Microsoft, and more.
Monitoring and tuning MapReduce and Hive applications in even the most complex processing pipelines.
Gaining insight into Hadoop resource consumption such as data storage, CPU, and memory usage across Hadoop clusters.
** DO NOT REMOVE Hidden Margin Required **
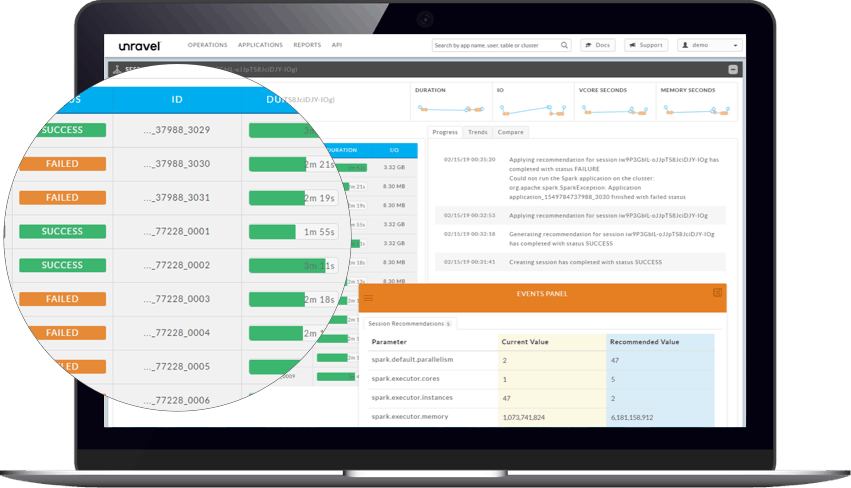
Predictive and proactive data operations for large Hadoop clusters
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Predictive and proactive data operations for large Hadoop clusters
Unravel uses advanced analytics, AI and ML to develop context and predictive insights into the complete Hadoop/Spark data management and processing pipeline.
Predict – and prevent – runaway Hadoop jobs that reduce the performance of other applications.
Improve planning and budgeting with comprehensive chargeback and showback views.
Proactively fix common issues automatically with Auto-Actions — rogue jobs, missed SLAs, misallocated resources, cold tables, and more.
** DO NOT REMOVE Hidden Margin Required **
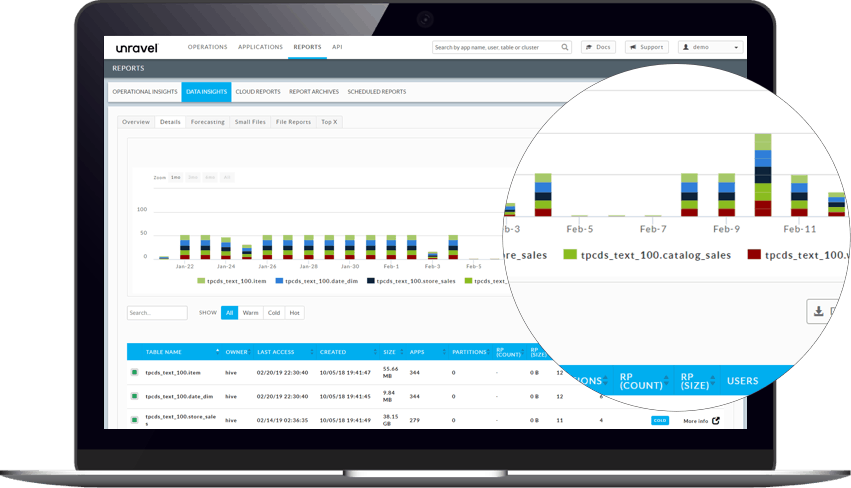
Unravel complements and extends existing Hadoop tooling
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Unravel informs administrators of all Hadoop and Spark ecosystem components with useful intelligence and time saving automation
Unravel adds intelligence to all stages of Spark/Hadoop data pipelines and provides a powerful new tool set for data operations teams. In relation to existing management and monitoring tools:
Unravel complements existing Hadoop monitoring and management tools such as Cloudera Manager and Apache Ambari.
Unravel is systematic machine intelligence for the full data stack, and can use predictive analytics to catch Hadoop and Spark issues before they happen.
Unravel provides intelligence to take advantage of both faster and cheaper storage solutions by tracking hot, warm, and cold data sets.