

The following blog post appeared in its original form on Towards Data Science. It’s part of a series on DataOps for effective AI/ML. The author is CDO and VP Engineering here at Unravel Data. (GIF by giphy)
Let’s start with a real-world example from one of my past machine learning (ML) projects: We were building a customer churn model. “We urgently need an additional feature related to sentiment analysis of the customer support calls.” Creating the data pipeline to extract this dataset took about 4 months! Preparing, building, and scaling the Spark MLlib code took about 1.5-2 months! Later we realized that “an additional feature related to the time spent by the customer in accomplishing certain tasks in our app would further improve the model accuracy” — another 5 months gone in the data pipeline! Effectively, it took 2+ years to get the ML model deployed!
After driving dozens of ML initiatives (as well as advising multiple startups on this topic), I have reached the following conclusion: Given the iterative nature of AI/ML projects, having an agile process of building fast and reliable data pipelines (referred to as DataOps) has been the key differentiator in the ML projects that succeeded. (Unless there was a very exhaustive feature store available, which is typically never the case).
Behind every successful AI/ML product is a fast and reliable data pipeline developed using well-defined DataOps processes!
To level-set, what is DataOps? From Wikipedia: “DataOps incorporates the agile methodology to shorten the cycle time of analytics development in alignment with business goals.”
I define DataOps as a combination of process and technology to iteratively deliver reliable data pipelines with agility. Depending on the maturity of your data platform, you might be one of the following DataOps phases:
- Ad-hoc: No clear processes for DataOps
- Developing: Clear processes defined, but accomplished manually by the data team
- Optimal: Clear processes with self-service automation for data scientists, analysts, and users.
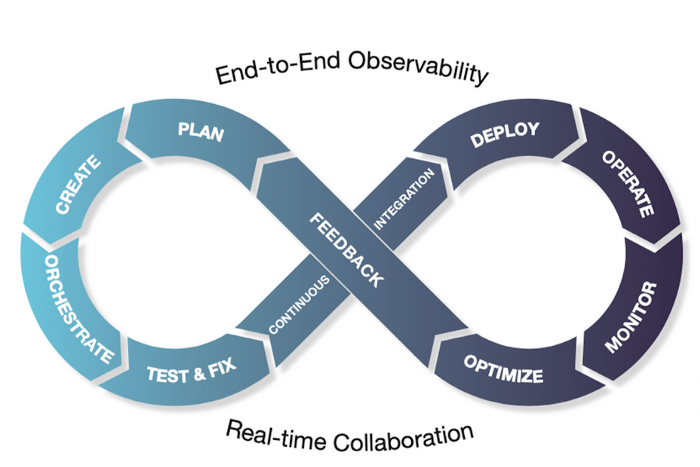
Similar to software development, DataOps can be visualized as an infinity loop
The DataOps lifecycle – shown as an infinity loop above – represents the journey in transforming raw data to insights. Before discussing the key processes in each lifecycle stage, the following is a list of top-of-mind battle scars I have encountered in each of the stages:
- Plan: “We cannot start a new project — we do not have the resources and need additional budget first”
- Create: “The query joins the tables in the data samples. I didn’t realize the actual data had a billion rows! ”
- Orchestrate: “Pipeline completes but the output table is empty — the scheduler triggered the ETL before the input table was populated”
- Test & Fix: “Tested in dev using a toy dataset — processing failed in production with OOM (out of memory) errors”
- Continuous Integration; “Poorly written data pipeline got promoted to production — the team is now firefighting”
- Deploy: “Did not anticipate the scale and resource contention with other pipelines”
- Operate & Monitor: “Not sure why the pipeline is running slowly today”
- Optimize & Feedback: “I tuned the query one time — didn’t realize the need to do it continuously to account for data skew, scale, etc.”
To avoid these battle scars and more, it is critical to mature DataOps from ad hoc, to developing, to self-service.
This blog series will help you go from ad hoc to well-defined DataOps processes, as well as share ideas on how to make them self-service, so that data scientists and users are not bottlenecked by data engineers.
Unlock your data environment health with a free health check.
For each stage of the DataOps lifecycle stage, follow the links for the key processes to define and the experiences in making them self-service (some of the links below are being populated, so please bookmark this blog post and come back over time):
Plan Stage
- How to streamline finding datasets
- Formulating the scope and success criteria of the AI/ML problem
- How to select the right data processing technologies (batch, interactive, streaming) based on business needs
Create Stage
- How to streamline accessing metadata properties of the datasets
- How to streamline the data preparation process
- How to make behavioral data self-service
Orchestrate Stage
- Managing Data Governance
- Re-using ML Model Features
- Scheduling data pipelines
Test & Fix Stage
- Streamlining sandbox environment for testing
- Identify and remove data pipeline bottlenecks
- Verify data pipeline results for correctness, quality, performance, and efficiency
Continuous Integration & Deploy Stage
- Smoke test for data pipeline code integration
- Scheduling window selection for data pipelines
- Changes rollback
Operate Stage
- Detect anomalies to proactively avoid SLA violation
- Managing data incidents in production
- Alerting on rogue (resource hogging) jobs
Monitor Stage
- Building end-to-end observability of data pipelines
- Tracking lineage of data flows data
- Enforcing data quality with circuit breakers
Optimize & Feedback Stage
- Continuously optimize existing data pipelines
- Alerting on budgets
In summary, DataOps is the key to delivering fast and reliable AI/ML! It is a team sport. This blog series aims to demystify the required processes as well as build a common understanding across Data Scientists, Engineers, Operations, etc.
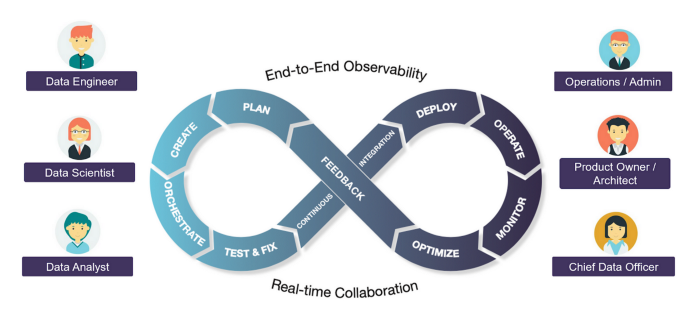
DataOps as a team sport
To learn more, check out the recent DataOps Unleashed Conference, as well as innovations in DataOps Observability at Unravel Data. Come back to get notified when the links above are populated.