

Table of Contents
DataOps Unleashed launched as a huge success, with scores of speakers, thousands of registrants, and way too many talks for anyone to take in all at once. Luckily, as a virtual event, all sessions are available for instant viewing, and attendees can keep coming back for more. (You can click here to see some of the videos, or visit Part 2 of this blog post.)
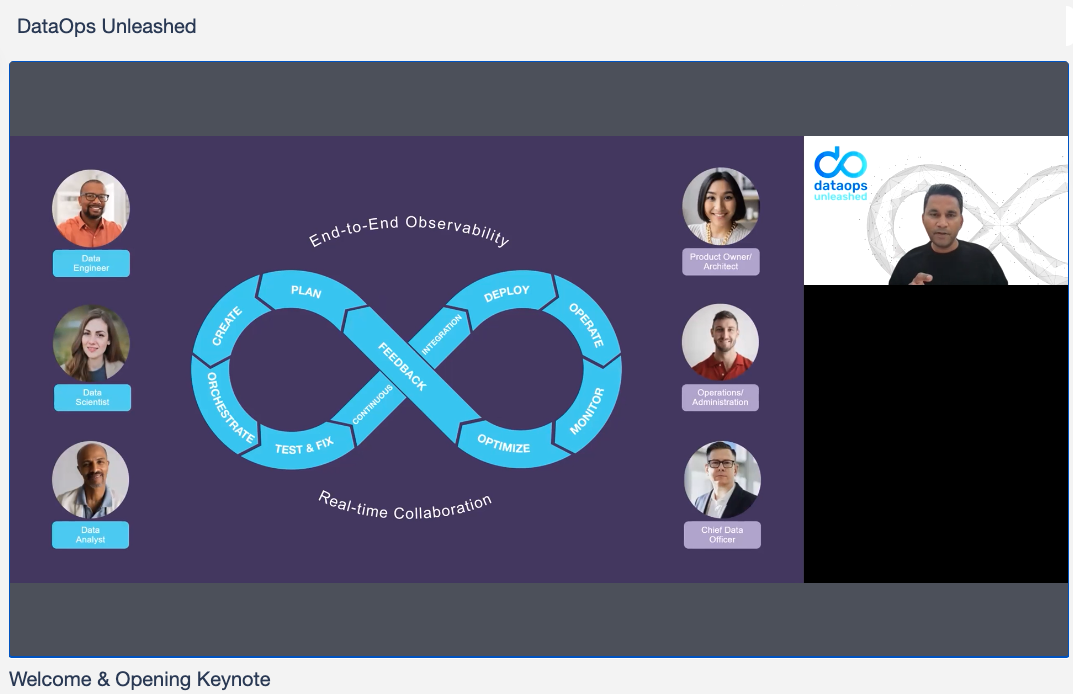
Kunal Agarwal, CEO of Unravel Data, kicked off the event with a rousing keynote, describing DataOps in depth. Kunal introduced the DataOps Infinity Loop, with ten integrated and overlapping stages. He showed how teams work together, across and around the loop, to solve the problems caused as both data flow and business challenges escalate.
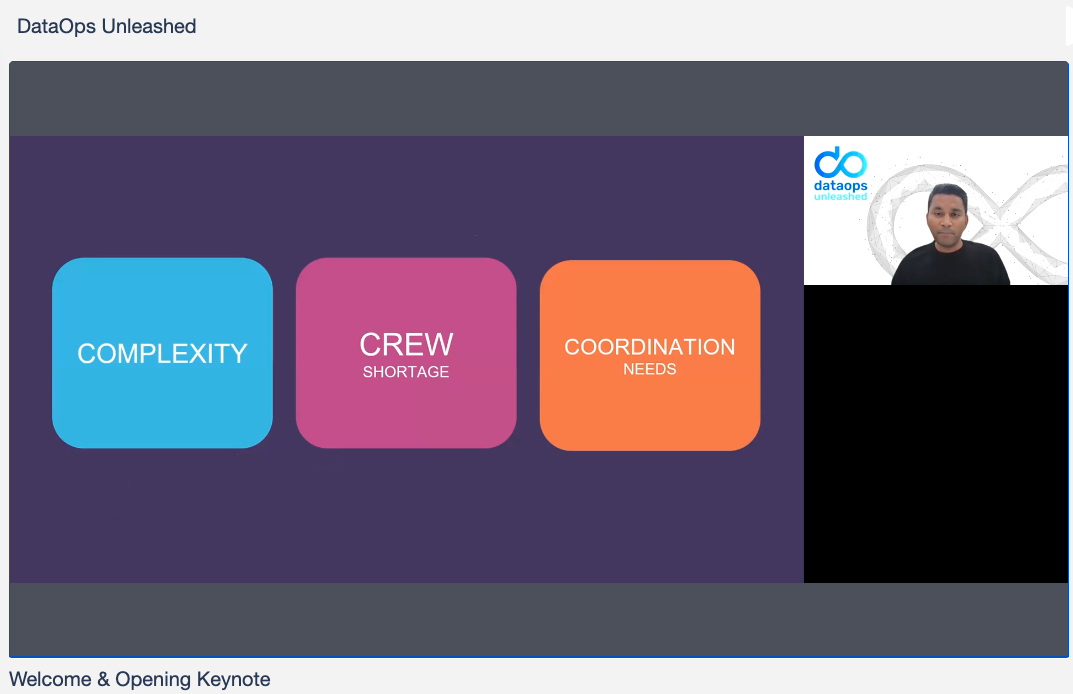
Kunal introduced three primary challenges that DataOps addresses, and that everyone assembled needs to solve, in order to make progress:
- Complexity. A typical modern stack and pipeline has about a dozen components, and the data estate as a whole has many more. All this capability brings power – and complexity.
- Crew. Small data teams – the crew – face staggering workloads. Finding qualified, experienced people, and empowering them, may be the biggest challenge.
- Coordination. The secret to team productivity is coordination. DataOps, and the DataOps lifecycle, are powerful coordination frameworks.
These challenges resonated across the day’s presentations. Adobe, Kroger, Cox Automotive, Mastercard, Astronomer, and Superconductive described the Unravel Data platform as an important ally in tackling complexity. And Vijay Kiran, head of data engineering at Soda, emphasized the role of collaboration in making teams effective. The lack of available talent to expand one’s Crew – and the importance of empowering one’s team members – came up again and again.
There were many highlights per presentation. A few that stand out from the morning sessions are Adobe, moving their entire business to the cloud; Airflow, a leader in orchestration; Cox Automotive, running a global business with a seven-person data team; and Great Expectations, which majors in data reliability.
How Adobe is Moving a $200B Business to the Cloud
Adobe was up next, with an in-depth cloud migration case study, covering the company’s initial steps toward cloud migration. Adobe is one of the original godfathers of today’s digital world, powering so much of the creativity seen in media, entertainment, on websites, and everywhere one looks. The company was founded in the early 1980s, and gained their original fame with Postscript and the laser printer. But the value of the business did not really take off until the past ten years, which is when the company moved from boxed software to a subscription business, using a SaaS model.
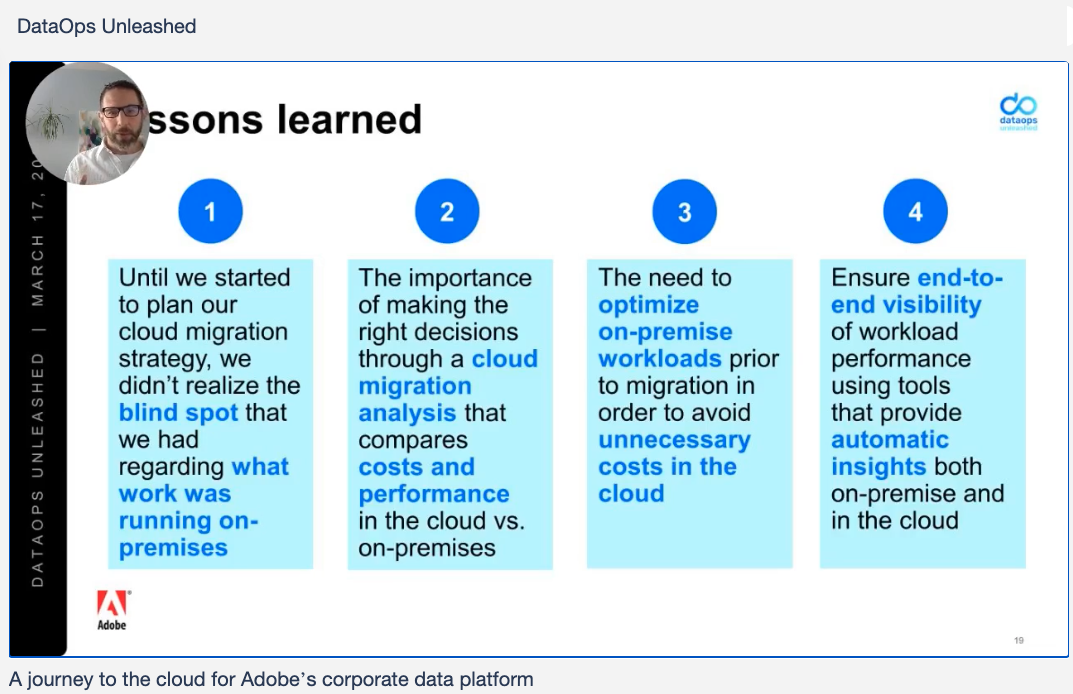
Now, Adobe is moving their entire business to the cloud. They describe four lessons they’ve learned in the move:
- Ignorance is not bliss. In planning their move to the cloud, Adobe realized that they had a large blind spot about what work was running on-premises. This may seem surprising until you check and realize that your company may have this problem too.
- Comparison-shop now. You need to compare your on-premises cost and performance per workload to what you can expect in the cloud. The only way to do this is to use a tool that profiles your on-premises workloads and maps each to the appropriate infrastructure and costs on each potential cloud platform.
- Optimize first. Moving an unoptimized workload to the cloud is asking for trouble – and big bills. It’s critically important to optimize workloads on-premises to reduce the hassle of cloud migration and the expense of running the workload in the cloud.
- Manage effectively. On-premises workloads may run poorly without too much hassle, but running workloads poorly in the cloud adds immediately, and unendingly, to costs. Effective management tools are needed to help keep performance high and costs under budget.
Kevin Davis, Application Engineering Manager, was very clear that Adobe has only gained the clarity they need through the use of Unravel Data for cloud migration, and for performance management, both on-premises and in the cloud. Unravel allows Adobe to profile their on-premises workloads; map each workload to appropriate services in the cloud; compare cost and performance on-premises to what they could expect in the cloud; optimize workloads on-premises before the move; and carefully manage workload cost and performance, after migration, in the cloud. Unravel’s automatic insights increase the productivity of their DataOps crew.
Unlock your data environment health with a free health check.
Cox Automotive Scales Worldwide with Databricks
Cox Automotive responded with a stack optimization case study. Cox Automotive is a global business, with wholesale and retail offerings supporting the lifecycle of motor vehicles. Their data services team, a mighty team of only seven people, supports the UK and Europe, offering reporting, analytics, and data sciences services to the businesses.
The data services team is moving from Hadoop clusters, deployed manually, to a full platform as a service (PaaS setup) using Databricks on Microsoft Azure. As they execute this transition, they are automating everything possible. Databricks allows them to spin up Spark environments quickly, and Unravel helps them automate pipeline health management.
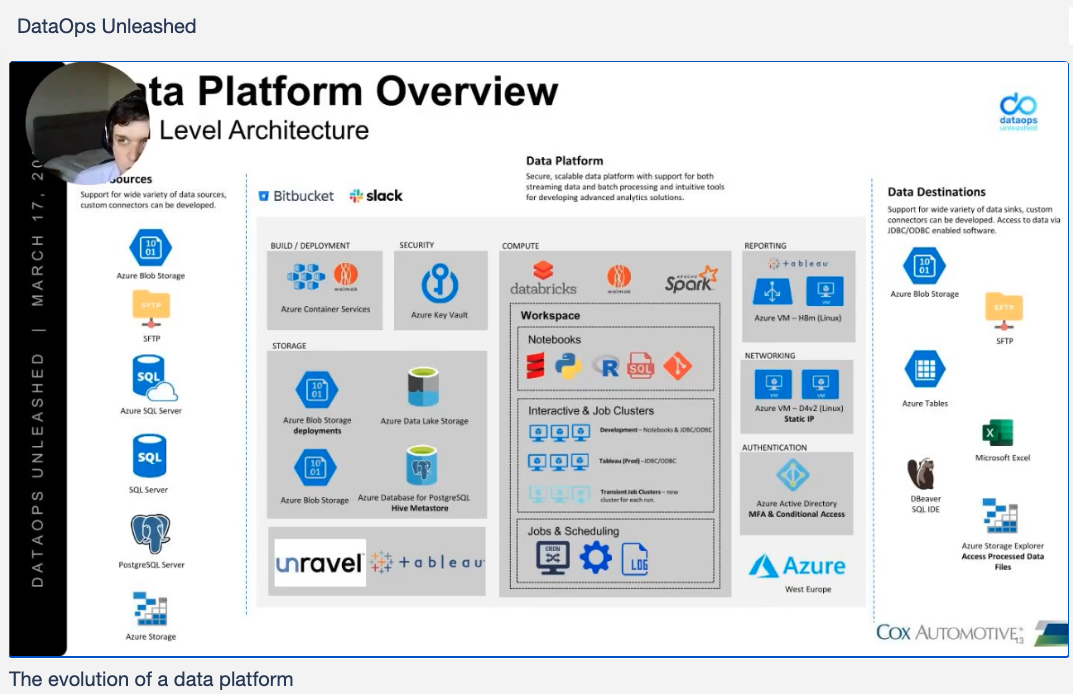
Data comes from a range of sources – mostly as files, with streaming expected soon. Cox finds Unravel particularly useful for optimization: choosing virtual machine types in Databricks, watching memory usage by jobs, making jobs run quicker, optimizing cost. These are all things that the team has trouble finding through other tools, and can’t readily build by themselves. They have an ongoing need for the visibility and observability that Unravel gives them. Unravel helps with optimization and is “really strong for observability in our platform.”
Great Expectations for Data Reliability
Great Expectations shared best practices on data reliability. Great Expectations is the leading open-source package for data reliability, which is crucial to DataOps success. An expectation is an assertion about data; when data falls outside these expectations, an exception is raised, making it easier to manage outliers and errors. Great Expectations integrates with a range of DataOps tools, making its developers DataOps insiders.SuperConductive provides support for Great Expectations and is a leading contributor to the open source project.
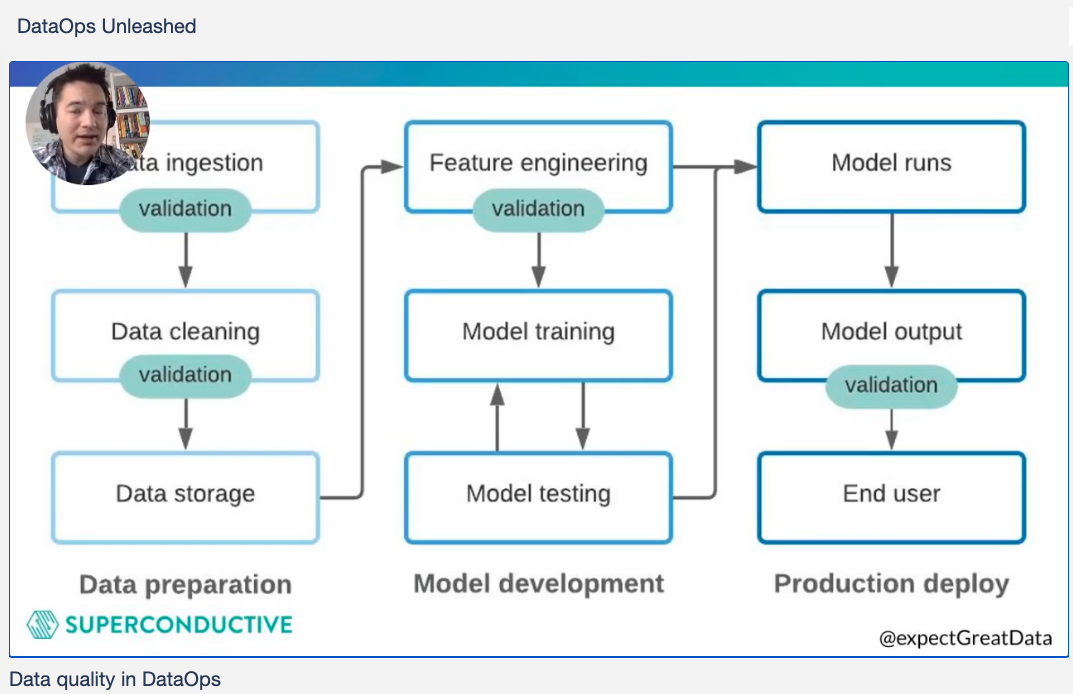
The stages where Great Expectations works map directly to the DataOps infinity loop. Static data must be prepared, cleaned, stored, and used for model development and testing. Then, when the model is deployed, live data must be cleansed, in real time, and run into and through the model. Results go out to users and apps, and quality concerns feed back to operations and development.
Airflow Enhances Observability
Astronomer conducted a master class on observability. Astronomer was founded to help organizations adopt Apache Airflow. Airflow is open source software for programmatically creating, scheduling, and monitoring complex workflows, including core DataOps tasks such as data pipelines used to feed machine learning models. To construct workflows, users create task flows called directed acyclic graphs (DAGs) in Python.
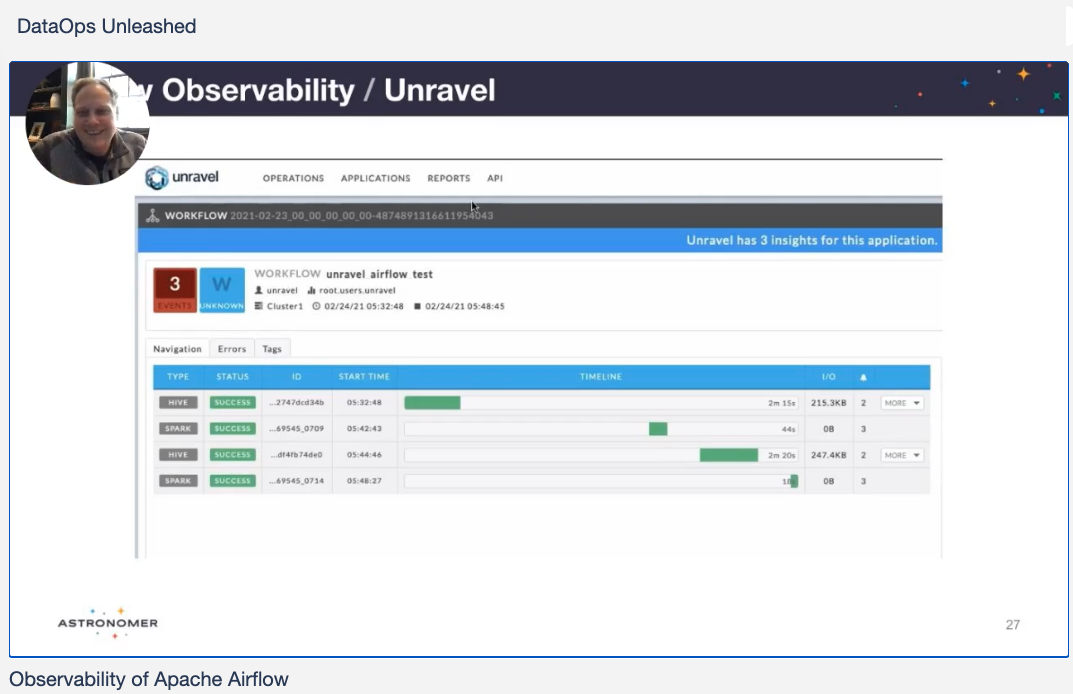
The figure shows a neat integration between Airflow and Unravel. Specifically, how Unravel can provide end-to-end observability and automatic optimization for Airflow pipelines. In this example it’s a simple DAG containing a few Hive and Spark stages. Data is passed from Airflow into Unravel via REST APIs, which helps create an easy to understand interface and then allows Unravel to generate automated insights for these pipelines.
DataOps Powers the New Data Stack
Unravel Data co-founder Shivnath Babu described and demystified the new data stack that is the focus of today’s DataOps practice. This stack easily supports new technologies such as advanced analytics and machine learning. However, this stack, while powerful, is complex, and operational challenges can derail its success.
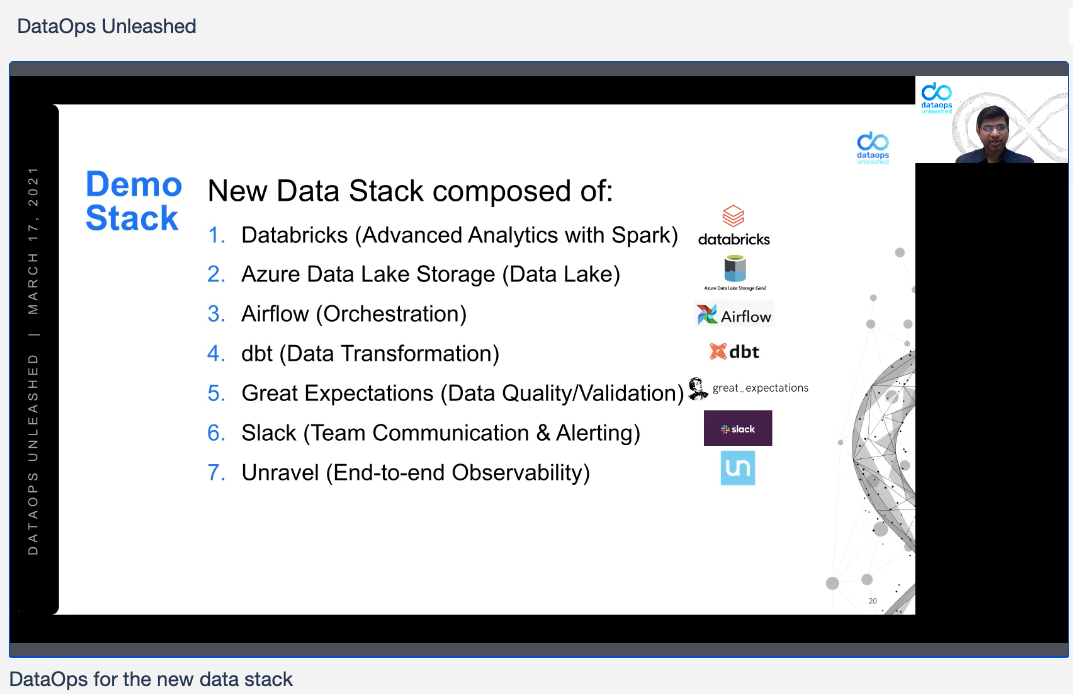
Shivnath showed an example of the new data stack, with Databricks providing Spark support, Azure Data Lake for storage, Airflow for orchestration, dbt for data transformation, and Great Expectations for data quality and validation. Slack provides communications and displays alerts, and Unravel Data provides end-to-end observability and automated recommendations for configuration management, troubleshooting, and optimization.
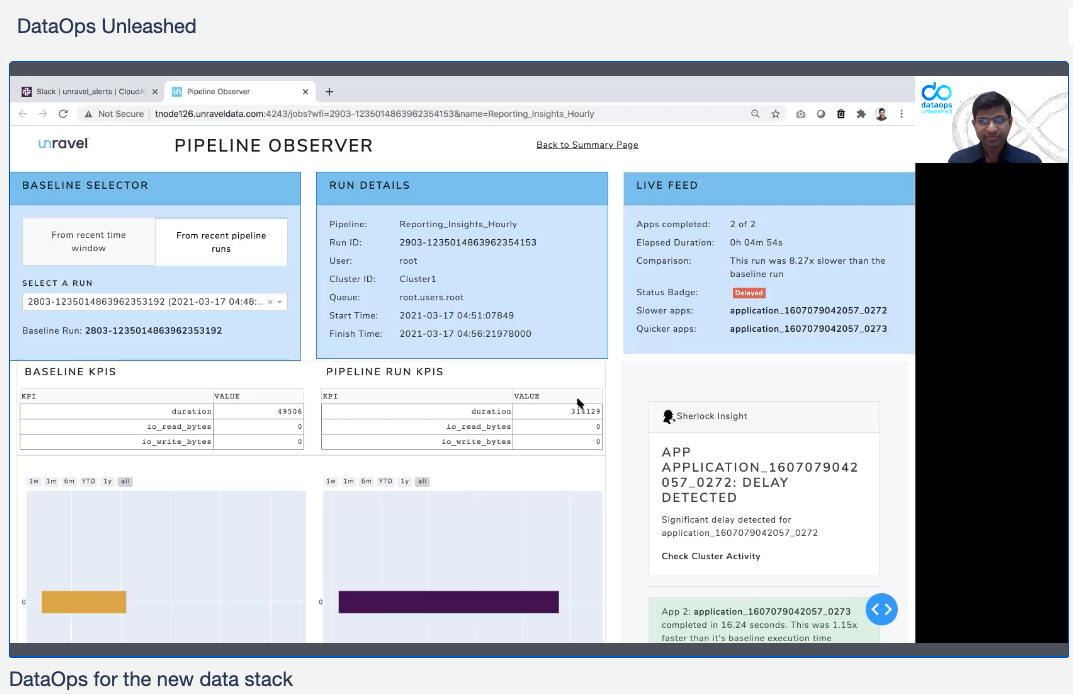
In Shivnath’s demo, he showed pipelines in danger of missing performance SLAs, overrunning on costs, or hanging due to data quality problems. Unravel’s Pipeline Observer allows close monitoring, and alerts feed into Slack.
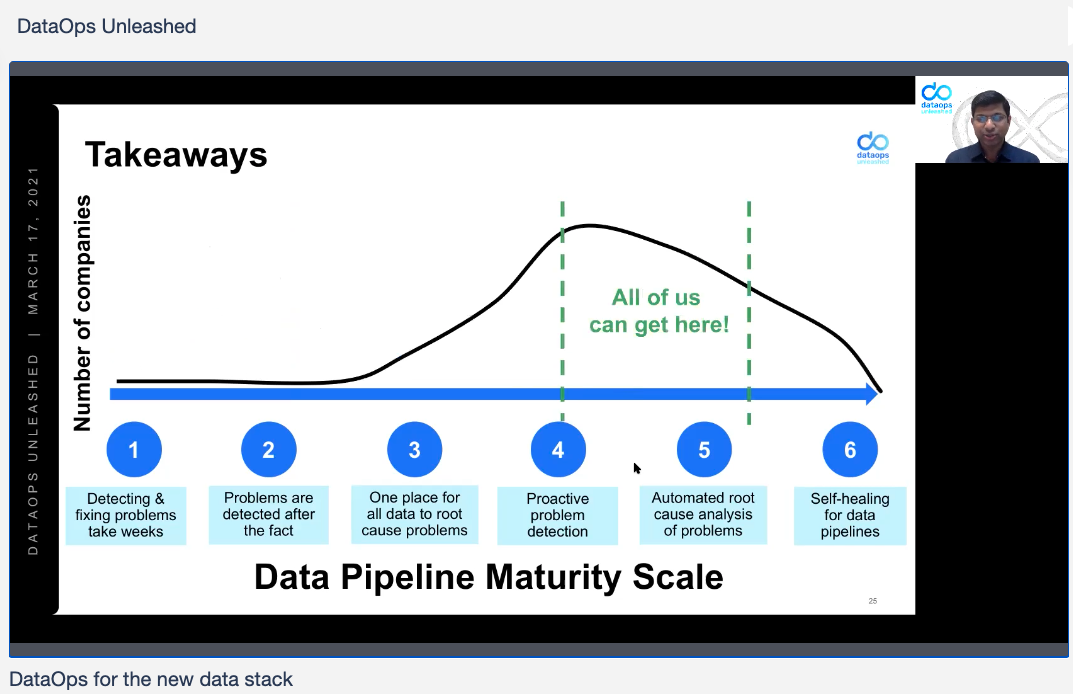
The goal, in Shivnath’s talk and across all of DataOps, is for companies to move up the data pipeline maturity scale – from problems detected after the fact, and fixed weeks later, to problems detected proactively, RCA’d (the root cause analyzed and found) automatically, and healing themselves.
Unlock your data environment health with a free health check.
OneWeb Takes the Infinity Loop to the Stars
To finish the first half of the day, OneWeb showed how to take Snowflake beyond the clouds – the ones that you can see in the sky over your head. OneWeb is a global satellite network provider that takes Internet connectivity to space, reaching anywhere on the globe. They are going to near-Earth orbit with Snowflake, using a boost from DataOps.live.
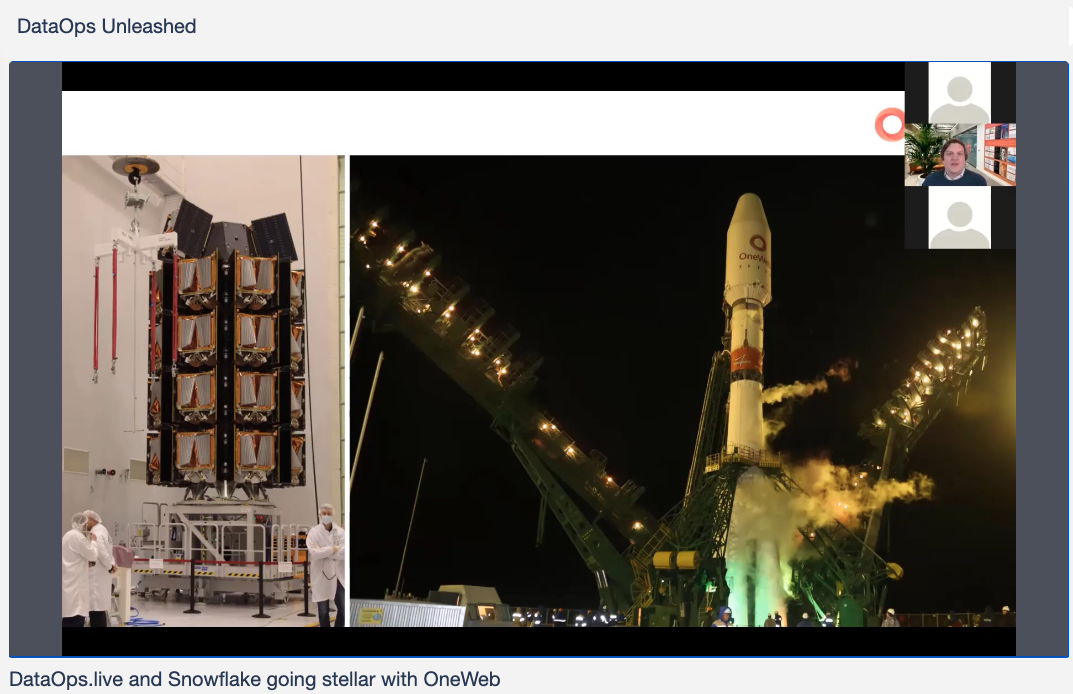
OneWeb connects to their satellites with antenna arrays that require lots of room, isolation – and near-perfect connectivity. Since customer connectivity can’t drop, reliability is crucial across their estate, and a DataOps-powered approach is a necessity for keeping OneWeb online.
One More Thing…
All of this is just part of what happened – in the first half of the day! We’ll provide a further update soon, including – wait for it – the state of DataOps, how to create a data-driven culture, customer case studies from 84.51°/Kroger and Mastercard, and much, much more. You can view the videos from DataOps Unleashed here. You can also download The Unravel Guide to DataOps, which was made available for the first time during the conference.
Finding Out More
Read our blog post Why DataOps Is Critical for Your Business.