

Table of Contents
DBS Bank leverages Unravel to identify inefficiencies across 10,000s of data applications/pipelines and guide individual developers and engineers on how, where, and what to improve—no matter what technology or platform they’re using.

DBS Bank is one of the largest financial services institutions in Asia—the biggest in Southeast Asia—with a presence in 19 markets. Headquartered in Singapore, DBS is recognized globally for its technological innovation and leadership, having been named World’s Best Bank by both Global Finance and Euromoney, Global Bank of the Year by The Banker, World’s Best Digital Bank by Euromoney (three times), and one of the world’s top 10 business transformations of the decade by Harvard Business Review. In addition, DBS has been given Global Finance’s Safest Bank in Asia award for 14 consecutive years.
DBS is, in its words, “redefining the future of banking as a technology company.” Says the bank’s Executive Director of Automation, Infrastructure for Big Data, AI, and Analytics Luis Carlos Cruz Huertas, “Technology is in our DNA, from the top down. Six years ago, when we started our data journey, the philosophy was that we’re going to be a data-driven organization, 100%. Everything we decide is through data.”
Realizing innovation and efficiency at scale and speed
DBS backs up its commitment to being a leading data-forward company. Almost 40% of the bank’s employees—some 23,000—are native developers. The volume, variety, and velocity of DBS’ data products, initiatives, and analytics fuel an incredibly complex environment. The bank has developed more than 200 data-use cases to deliver business value: detecting fraud, providing value to customers via their DBS banking app, and providing hyper personalized “nudges” that guide customers in making more informed banking and investment decisions.
As with all financial services enterprises, the DBS data estate is a multi-everything mélange: on-prem, hybrid, and several cloud providers; all the principal platforms; open source, commercial, and proprietary solutions; and a wide variety of technologies, old and new. Adding to this complexity are the various country-specific requirements and restrictions throughout the bank’s markets. As Luis says, “There are many ways to do the cloud, but there’s also the banking way to do cloud. Finance is ring-fenced by regulation all over the world. To do cloud in Asia is quite complex. We don’t [always] get to choose the cloud, sometimes the cloud chooses us.” (For example, India now requires all data to run in India. Google was the only cloud available in Indonesia at the time. Data cannot leave China; there are no hyperscalers there other than Chinese.)
See the conversation here
The pace of today’s innovation at a data-forward bank like DBS makes ensuring efficient, reliable performance an ever-growing challenge.
Today DBS runs more than 40,000 data jobs, with tens of thousands of ML models. “And that actually keeps growing,” says Luis. “We have exponentially grown—almost 100X what we used to run five years ago. There’s a lot of innovation we’re bringing, month to month.”
As Luis points out, “Sometimes innovation is a disruptor of stability.” With thousands of developers all using whatever technologies are best-suited for their particular workload, DBS has to contend with the triple-headed issues of exponentially increasing data volumes (think: OpenAI); increasingly more technologies, platforms, and cloud providers; and the ever-present challenge of having enough skilled people with enough time to ensure that everything is running reliably and efficiently on time, every time—at population scale.
DBS empowers self-service optimization
One of DBS’ lessons learned in its modern data journey is that, as Luis says, “a lot of the time the efficiencies relied on the engineering team to fix the problems. We didn’t really have a viable mechanism to put into the [business] users’ hands for them to analyze and understand their code, their deficiencies, and how to improve.”
That’s where Unravel comes in. The Unravel platform harnesses deep full-stack visibility, contextual awareness, AI-powered intelligence, and automation to not only quickly show what’s going on and why, but provide crisp, prescriptive recommendations on exactly how to make things better and then keep them that way proactively.
“In Unravel, [we] have a source to identify areas of improvement for our current operational jobs. By leveraging Unravel, we’ve been able to put an analytical tool in the hands of business users to evaluate themselves before they actually do a code release. [They now get] a lot of additional insights they can use to learn, and it puts a lot more responsibility into how they’re doing their job.”
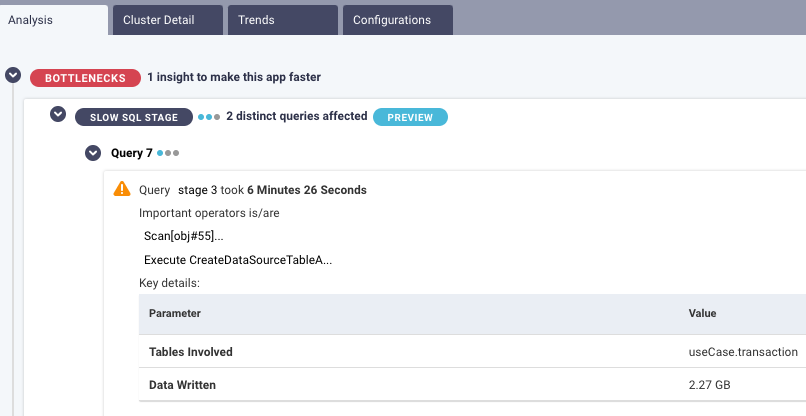
To learn more about how Unravel puts self-service performance and cost optimization capabilities into the hands of individual engineers, see the Unravel Platform Overview.
Marrying data engineering and data science
DBS is perpetually innovating with data—40% of the bank’s workforce are data science developers—yet the scale and speed of DBS’ data operations bring the data engineering side of things to the forefront. As Luis points out, there are thousands of developers committing code but only a handful of data engineers to make sure everything runs reliably and efficiently.
While few organizations have such a high percentage of developers, virtually everyone has the same lopsided developer : engineer ratio. Tackling this reality is at the heart of DataOps and means new roles, where data science and data engineering meet. Unravel has helped facilitate this new intersection of roles and responsibilities by making it easier to pinpoint code inefficiencies and provide insights into what, where, and how to optimize code — without having to “throw it over the fence” to already overburdened engineers.
Luis discusses how DBS addresses the issue: “In hardware, you have something called system performance engineers. They’re dedicated to optimizing and tuning how a processor operates, until it’s pristine. I said, ‘Why don’t we apply that concept and bring it over to data?’ What we need is a very good data scientist who wants to learn data engineering. And a data engineer who wants to become a data scientist. Because I need to connect and marry both worlds. It’s the only way a person can actually say, ‘Oh, this is why pandas doesn’t work in Spark.’ For a data engineer, it’s very clear. For a data scientist, it’s not. Because the first thing they learned in Python is pandas. And they love it. And Spark hates it. It’s a perfect divorce. So we need to teach data scientists how to break their pandas into Spark. Our system performance engineers became masters at doing this. They use Unravel to highlight all the data points that we need to attack in the code, so let’s just go see it.
“We call data jobs ‘mutants,’ because they mutate from the hands of one data scientist to another. You can literally see the differences on how they write the code. Some of it might be perfect, with Markdown files, explainability, and then there’s an entire chunk of code that doesn’t have that. So we tune and optimize the code. Unravel helps us facilitate the journey on deriving what to do first, what to attack first, from the optimization perspective.”
DBS usually builds their own products—why did they buy Unravel?
DBS has made the bold decision to develop its own proprietary technology stack as wrappers for its governance, control plane, data plane, etc. “We ring-fence all compute, storage, services—every resource the cloud provides. The reason we create our own products is that we’ve been let down way too many times. We don’t really control what happens in the market. It’s the world we live in. We accept that. Our data protection mechanism used to be BlueTalon, which was then acquired by Microsoft. And Microsoft decided to dispose of [BlueTalon] and use their own product. Our entire security framework depended on BlueTalon. . . . We decided to just build our own [framework].
“In a way DBS protects itself from being forced to just do what the providers want us to do. And there’s a resistance from us—a big resistance—to oblige that.” Luis uses a cooking analogy to describe the DBS approach. At one extreme is home cooking, where you go buy all the ingredients and make meals yourself. At the other end of the spectrum is going out to restaurants, where you choose items from the menu and you get a meal the way they prepare it. The DBS data platform is more like a cooking studio—Luis provides the kitchen, developers pick the ingredients they want, and then cook the recipe with their own particular flavor. “That’s what we provide to our lines of business,” says Luis. “The good thing is, we can plug in anything new at any given point in time. The downside is that you need very, very good technical people. How do we sustain the pace of rebuilding new products, and keep up with the open source side, which moves astronomically fast—we’re very connected to the open source mission, close to 50% of our developers contribute to the open source world—and at the same time keep our [internal and external] customers happy?”
Find out here
Luis explains the build vs. buy decision boils down to whether the product “drives the core of what we do, whether it’s the ‘spinal cord’ of what we do. We’ve had Unravel for a long, long time. It’s one of those products where we said, ‘Should we do it [i.e., build it ourselves]? Or should we find something on the market?’ With Unravel, it was an easy choice to say, ‘If they can do what they claim they can do, bring ’em in.’ We don’t need to develop our own [data observability solution]. Unravel has demonstrated value in [eliminating] hours of toil—nondeterministic tasks performed by engineers because of repetitive incidents. So, long story short: that [Unravel] is still with us demonstrates that there is value from the lines of business.”
Luis emphasizes his data engineering team are not the users of Unravel. “The users are the business units that are creating their jobs. We just drive adoption to make sure everyone in the bank uses it. Because ultimately our data engineers cannot ‘overrun’ a troop of 3,000 data scientists. So we gave [Unravel] to them, they can use it, they can optimize, and control their own fate.”
DBS realizes high ROI from Unravel
Unravel’s granular data observability, automation, and AI enable DBS to control its cloud data usage at the speed and scale demanded by today’s FinServ environment. “Unravel has saved potentially several $100,000s in [unnecessary] compute capacity,” says Luis. “This is a very big transformational year for us. We’re moving more and more into some sort of data mesh and to a more containerized world. Unravel is part of that journey and we expect that we’ll get the same level of return we’ve gotten so far—or even better.”