

Explore All in This Collection
Table of Contents
At the DataOps Unleashed 2022 conference, Google Cloud’s Head of Product Management for Open Source Data Analytics Abhishek Kashyap discussed how businesses are using Google Cloud to build secure and scalable data platforms. This article summarizes key takeaways from his presentation, Building a Scalable Data Platform with Google Cloud.
Data is the fuel that drives informed decision-making and digital transformation. Yet major challenges remain when it comes to tackling the demands of data at scale.
The world’s datasphere reached 33 zettabytes in 2018. IDC estimates that it will grow more than fivefold by 2025 to reach 175 zettabytes.
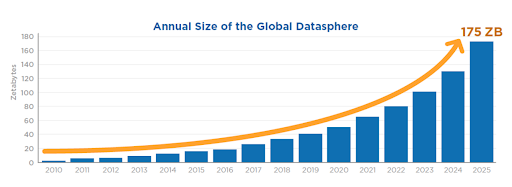
IDC estimates the datasphere to grow to 175ZB by 2025.
From data to value: A modern journey
“Building a [modern] data platform requires moving from very expensive traditional [on-prem] storage to inexpensive managed cloud storage because you’re likely going to get to petabytes—hundreds of petabytes of data—fairly soon. And you just cannot afford it with traditional storage,” says Abhishek.
He adds that you need real-time data processing for many jobs. To tie all the systems together—from applications to databases to analytics to machine learning to BI—you need “an open and flexible universal system. You cannot have systems which do not talk to each other, which do not share metadata, and then expect that you’ll be able to build something that scalable,” he adds.
Further, you need a governed and scalable data sharing systems, as well as build machine learning into your pipelines, your processes, your analytics platform. “If you consider your data science team as a separate team that does special projects and needs to download data into their own cluster of VMs, it’s not going to work out,” says Abhishek.
And finally, he notes, “You have to present this in an integrated manner to all your users to platforms that they use and to user interfaces they are familiar with.”

The benefits of a modern data platform vs. traditional on-prem
The three tenets of a modern data platform
Abhishek outlined three key tenets of a modern data platform:
- Scalability
- Security and governance
- End-to-end integration
And showed how Google Cloud Platform addresses each of these challenges.
Scalability
Abhishek cited an example of a social media company that has to process more than a trillion messages each day. It has over 300 petabytes of data stored, mostly in BigQuery, and is using more than half a million compute cores. This scale is achievable because of two things: the separation of compute and storage, and being serverless.
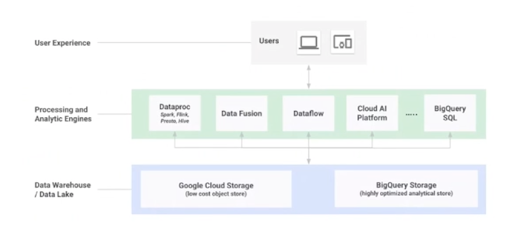
The Google Cloud Platform divorces storage from compute
By segregating storage from compute, “you can run your processing and analytics engine of choice that will scale independently of the storage,” explains Abhishek. Google offers a low-cost object store as well as an optimized analytical store for data warehousing workloads, BigQuery. You can run Spark and Dataproc, Dataflow for streaming, BigQuery SQL for your ETL pipelines, Data Fusion, your machine learning models on Cloud AI Platform—all without tying any of that to the underlying data so you can scale the two separately. Google has multiple customers who have run queries on 100,000,000,000,000 (one hundred trillion) rows on BigQuery, with one running 10,000 concurrent queries.
“Talk to any DBA or data engineer who’s working on a self-managed Hadoop cluster, or data warehouse on prem, and they’ll tell you how much time they spent in thinking about virtual machines resource provisioning, fine tuning, putting in purchase orders, because they’ll need to scale six months from now, etc, etc. All that needs to go away,” says Abhishek. He says if users want to use the data warehouse, all they think about is SQL queries. If they use Spark, all they think about is code.
Google has serverless products for each step of the data pipeline. To ingest and distribute data reliably, there’s the serverless auto-scaling messaging queue Pub/Sub, Dataproc for serverless Spark, Dataflow for serverless Beam, and BigQuery (the first serverless data warehouse) for analysis.
Watch presentation on demand
Security and governance
With data at this scale, with users spread across business units and data spread across a variety of sources, security and governance must be automated. You can’t be manually filing tickets for every access request or manually audit everything—that just doesn’t scale.
Google has a product called Dataplex, which essentially allows you to take a logical view of all your data spread across data warehouses, data lakes, data marts and build a centralized governed set of data lakes whose life cycle you can manage. Let’s say you have structured, semi-structured, and streaming data stored in a variety of places and you have analytics happening through BigQuery SQL or through Spark or Dataflow. Dataplex provides a layer in the middle that allows you to set up automatic data discovery, harvesting metadata, doing things like reading a file from objects to provide it as a table in BigQuery, metadata where it’s going, to ensure data quality.
So you store your data where your applications need it, split your applications from the data, and have Dataplex manage security, governance, and lifecycle management for these data lakes.
End-to-end integration
Effective data analytics ultimately serve to make data-driven insights available to anyone in the business who needs them. End-to-end integration with the modern data stack is crucial so that the platform accommodates the various tools that different teams are using—not the other way around.
The Google Cloud Platform does this by enhancing the capabilities of the enterprise data warehouse—specifically, BigQuery. BigQuery consolidates data from a variety of places to make it available for analytics in a secure way through the AI Platform, Dataproc for Spark jobs, Dataflow for streaming, Data Fusion for code-free ETL. All BI platforms work with it, and there’s a natural language interface so citizen data scientists can work with it.
This allows end users to all work through the same platform, but doing their work through languages and interfaces of their choice.
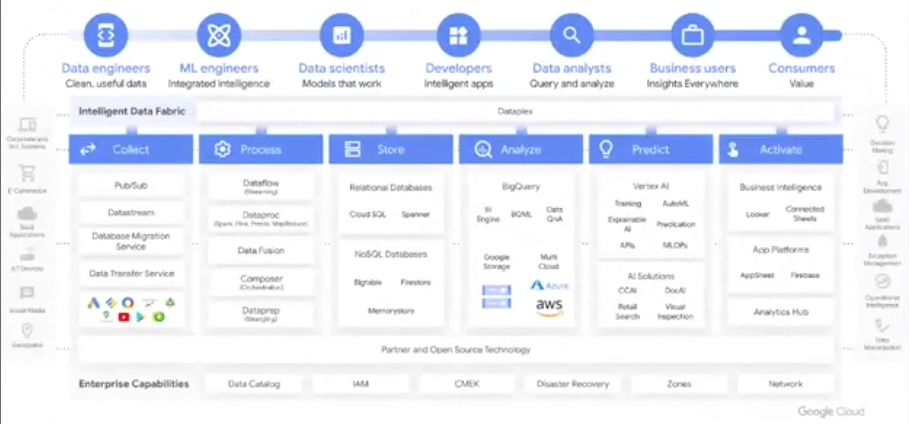
Google offering for each stage of the data pipeline
Request a free account
Wrapping up
Abhishek concludes with an overview of the products that Google offers for each stage of the data pipeline. “You might think that there are too many products,” Abhishek says. “But if you go to any customer that’s even medium size, what you’ll find is different groups have different needs, they work through different tools. You might find one group that loves Spark, you might find another group that needs to use Beam, or third groups wants to use SQL. So to really help this customer build an end-to-end integrated data platform, we provide this fully integrated, very sophisticated set of products that has an interface for each of the users who needs to use this for the applications that they build.”
See how Unravel takes the risk out of managing your Google Cloud Platform migrations.