

Table of Contents
84.51° is a wholly owned subsidiary of Kroger, the US retailing giant – the largest supermarket chain in America, and the fifth-largest retailer in the world. As an organization, 84.51° is a descendant of dunnhumby, analytics geniuses who revolutionized customer loyalty programs at Tesco in the UK decades ago. Today, 84.51° provides loyalty programs and deep analytics, AI, and machine learning support to Kroger, as well as many of its suppliers and partners – more than a thousand companies in total.
84.51° is a big data innovator that ran into operational problems – many of the problems that Unravel Data was founded to solve. They have been able to use Unravel to resolve these problems, cut costs, improve operational efficiency, and open the door for innovation. These improvements benefit all of their customers and stakeholders, as well as the consumers who fuel all the businesses involved.

At the DataOps Unleashed conference last month, 84.51° led a mainstage presentation to share how they have solved problems and opened up new opportunities using Unravel. This story, and the slides and videos included in it, come from the presentation.
Controlling Costs
The original problem facing 84.51° senior management was uncontrolled costs on Hadoop, running on-premises. The big data operation was like an overworked steam boiler that was threatening to explode. Resources were stretched to the limit, yet there was no guarantee that bringing in more resources would solve operational problems. Hadoop admins were stretched thin, yet customer requirements constantly tasked them to try to do even more.
Faced with these challenges, management set a series of goals for the big data operation, cutting across a wide range of concerns:
- Lower capex. Capital expenditures on-premises were too high. Selected workloads could usefully be moved to Databricks and Snowflake on Azure, and others potentially to Google Cloud Platform, but the workloads had to be optimized first.
- Cluster inefficiency. Clusters were memory-constrained and jobs were run inefficiently. Administrators lacked visibility needed to solve operational problems and plan more efficient job orchestration.
- Small files. Some jobs generated tens of thousands of small files, which consumed resources out of proportion to their size and importance.
- Help developers. Developers were feeding unoptimized code into the system, with no quick and easy way to optimize it, nor any good way to learn best principles for creating code that ran more efficiently in production.
- Offload administrators. Overloaded administrators needed automation for routine tasks, useful alerts, and recommendations as to how to fix, and even prevent problems.

Jeff Lambert is VP of Data Solutions at 84.51°. He provides several illuminating quotes as to what he was being asked by overwhelmed operators and management:
- “Hey Lambert, we need you to help control some of the costs that are going on within the organization.”
- “I don’t want to buy any more Hadoop just because we’re lazy. Let’s figure out how to actually optimize it.”
- “Hey, people are jamming up our Hadoop resources. I can’t get my work done because people are being inefficient in what we’re trying to do.”
- “I’m running this on-prem – how much is it gonna actually take me to run it on Azure?”
Management wanted to pivot from chasing problems to working on proactive improvements in Hadoop, both to reduce problems going forward and to optimize and profile workloads for migration to the cloud.
Unravel Data to the Rescue
84.51° was introduced to Unravel Data, and immediately began to solve some of their problems. But they wanted to put key functionality in one place – and, as data science experts, they knew just what they needed.
So Lambert worked with Unravel Data to develop a dashboard that brings key metrics together, grouping them into a single, easy-to-grasp summary. Lambert estimates that it cuts his workload for aggregating information to 10% of what it had previously been.
“One thing that Unravel’s really great at,” continues Lambert, “is pointing out to you the things that were actually causing the most pain and suffering across the two main clusters that we have within our world.”
With Unravel, costs can be identified, and inefficient jobs can easily be profiled for optimization. According to Lambert, “Unravel gives a profile to our execs, with fine-grained user information about who is doing what and what they’re actually consuming. As a result, we’re now in a much better place than where we were initially. The people at Unravel made it easier for me, and I appreciate that.”
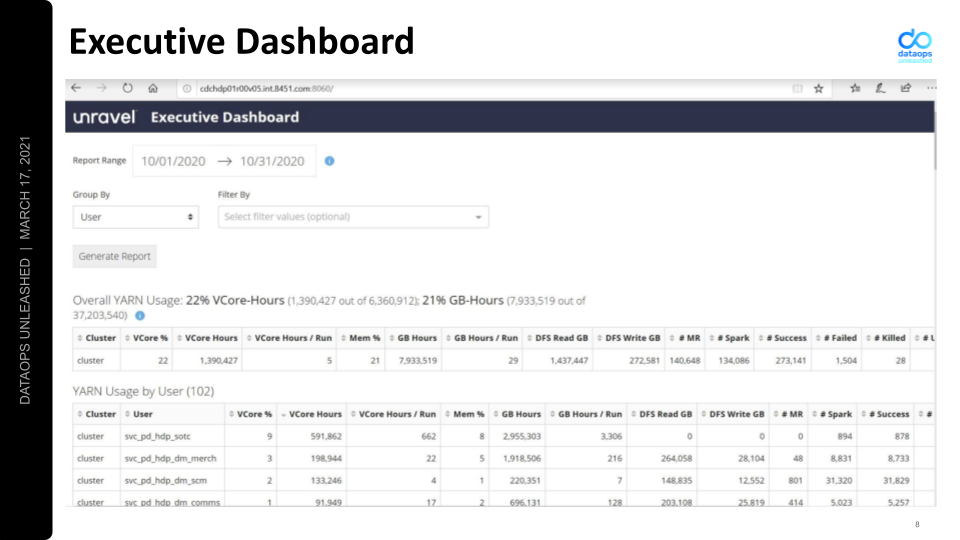
People across the company responded to the new information, and developers have integrated Unravel into their processes, pre-release. They use Unravel as a final check for their Spark configurations and the settings for new and modified jobs. As a result, jobs are optimized before they even reach production.
The new dashboard created for 84.51° is so effective that other Unravel customers have adopted it as well. And more companies are also looking to integrate Unravel into their software development process.
Take the Unravel tour
Double-Clicking on Optimization
Suresh Deevarakonda is lead engineer for database, Exadata, and Hadoop administration at 84.51°. Here’s a snapshot of the Unravel environment he manages.
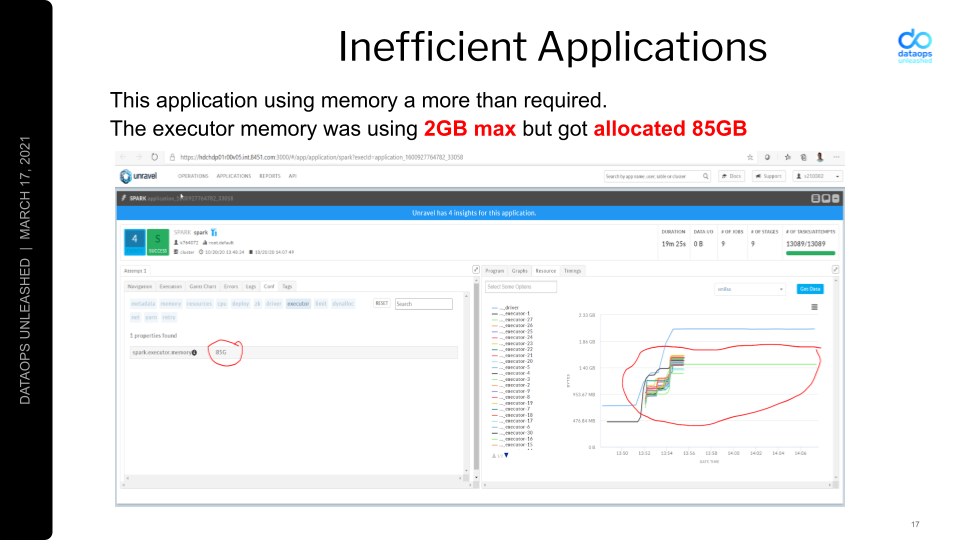
Sareesh points out an example of an inefficient application configuration – wherein the application maxes out at 2GB of memory usage, but has been allocated 85GB. “We were wasting a lot of memory on that one stack. We are identifying those applications and correcting them.”
“And we are going to automate that process,” Sareesh continues. “Whenever there’s an inefficient application, data will be sent to the owner of the job so that they can fix the jobs themselves, so we don’t need to follow up with them.”
84.51° uses Unravel’s Auto Actions to identify resource contention, rogue applications, and rogue users. With Unravel, problems that formerly took half an hour or more to track down now get solved in just a few minutes. For example, a job that took 22 minutes to run has been optimized to run in 12 minutes, using Unravel recommendations.
Eliminating Excess Small Files
Across the big data world, some jobs tend to generate excessive numbers of small files. 84.51° has Kroger as a huge customer, and more than a thousand CPG customers as well – all cooperating and competing to best serve consumers, often by coming up with new ideas and approaches for data science, AI, machine learning, and analytics. So problems like the small files issue come up frequently in their work.
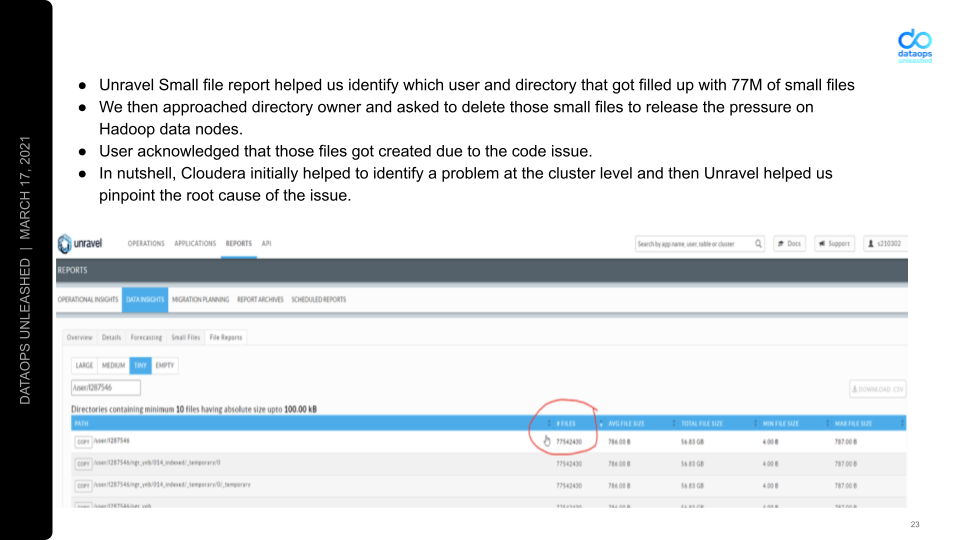
“Unravel is really helping us out,” says Sareesh. “We scheduled the small file report, and one user created 177 million records. We approached the user and identified a code issue. Immediately, we deleted those small files and brought that cluster back to normal. This is a very helpful and cool thing, and especially in our new cloud environment.”
Unravel even helps 84.51° admins be better at their jobs. Sareesh comes from a database background. With Unravel, he was quickly able to start managing Hadoop administration and Spark application management, even before having the opportunity to master all the intricacies of these big data technologies.
Test-drive Unravel for Spark
Expanding the Partnership
What’s next for 84.51° with Unravel? According to Lambert, “We want to be able to use Unravel’s migration and optimization tools to understand how much it’s gonna take to run jobs in different areas and locations, as well as the associated cost.” Unravel is not just helping 84.51° to troubleshoot and optimize jobs in a specific environment; it’s helping them find the right environment for every job.

While this blog post gives a flavor for what 84.51° is accomplishing with Unravel Data, you can get the whole story by viewing the 84.51° presentation by Jeff and Sareesh. You can view all the videos from DataOps Unleashed here. And you can download The Unravel Guide to DataOps, made available for the first time during the conference. If you’re interested in assessing Unravel for your own data-driven applications, you can create a free account or contact us to learn how we can help.