

Table of Contents
In this fast-paced era of artificial intelligence (AI), the need for data is multiplying. The demand for faster data life cycles has skyrocketed, thanks to AI’s insatiable appetite for knowledge. According to a recent McKinsey survey, 75% expect generative AI (GenAI) to “cause significant or disruptive change in the nature of their industry’s competition in the next three years.”
Next-gen AI craves unstructured, streaming, industry-specific data. Although the pace of innovation is relentless, “when it comes to generative AI, data really is your moat.”
But here’s the twist: efficiency is now the new cool kid in town. Data product profitability hinges on optimizing every step of the data life cycle—from ingestion and transformation, to processing, curating, and refining. It’s no longer just about gathering mountains of information; it’s about collecting the right data efficiently.
As new, industry-specific GenAI use cases emerge, there is an urgent need for large data sets for training, validation, verification, and drift analysis. GenAI requires flexible, scalable, and efficient data architecture, infrastructure, code, and operating models to achieve success.
Leverage a Scalable Operating Model to Accelerate Your Data Life Cycle Velocity
To optimize your data life cycle, it’s crucial to leverage a scalable operating model that can accelerate the velocity of your data processes. By following a systematic approach and implementing efficient strategies, you can effectively manage your data from start to finish.
Databricks recently introduced a scalable operating model for data and AI to help customers achieve a positive Return on Data Assets (RODA).
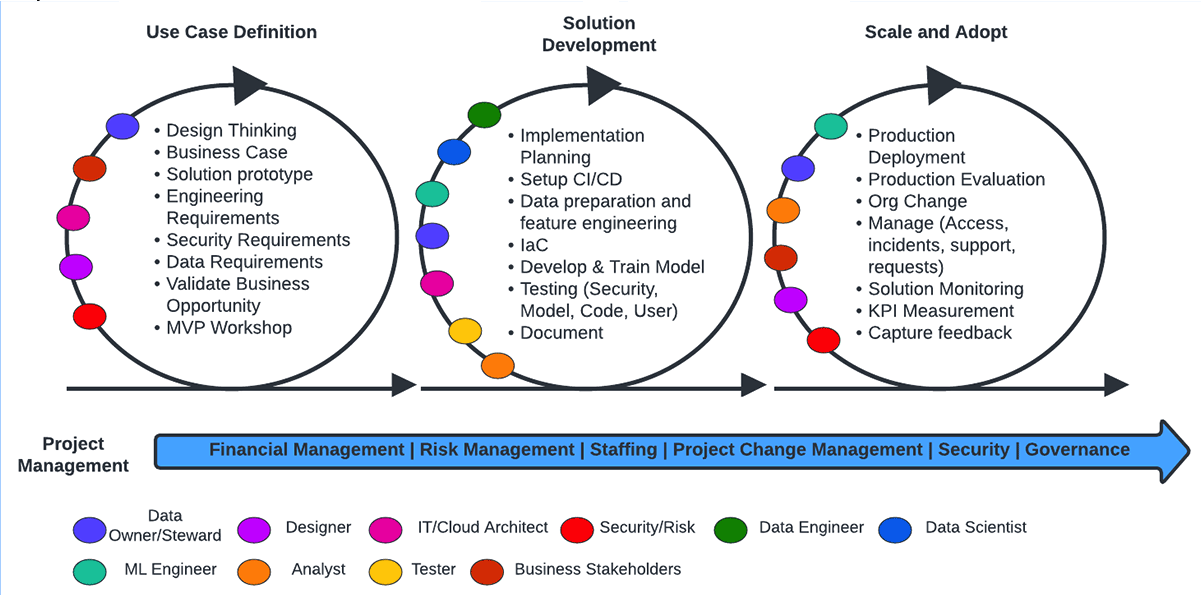
Databricks’ iterative end-to-end operating pipeline
Define Use Cases and Business Requirements
Before diving into the data life cycle, it’s essential to clearly define your use cases and business requirements. This involves understanding what specific problems or goals you plan to address with your data. By identifying these use cases and related business requirements, you can determine the necessary steps and actions needed throughout the entire process.
Build, Test, and Iterate the Solution
Once you have defined your use cases and business requirements, it’s time to build, test, and iterate the solution. This involves developing the necessary infrastructure, tools, and processes required for managing your data effectively. It’s important to continuously test and iterate on your solution to ensure that it meets your desired outcomes.
During this phase, consider using agile methodologies that allow for quick iterations and feedback loops. This will enable you to make adjustments as needed based on real-world usage and feedback from stakeholders.
Scale Efficiently
As your data needs grow over time, it’s crucial to scale efficiently. This means ensuring that your architecture can handle increased volumes of data without sacrificing performance or reliability.
Consider leveraging cloud-based technologies that offer scalability on-demand. Cloud platforms provide flexible resources that can be easily scaled up or down based on your needs. Employing automation techniques such as machine learning algorithms or artificial intelligence can help streamline processes and improve efficiency.
By scaling efficiently, you can accommodate growing datasets while maintaining high-quality standards throughout the entire data life cycle.
Elements of the Business Use Cases and Requirements Phase
In the data life cycle, the business requirements phase plays a crucial role in setting the foundation for successful data management. This phase involves several key elements that contribute to defining a solution and ensuring measurable outcomes. Let’s take a closer look at these elements:
- Leverage design thinking to define a solution for each problem statement: Design thinking is an approach that focuses on understanding user needs, challenging assumptions, and exploring innovative solutions. In this phase, it is essential to apply design thinking principles to identify and define a single problem statement that aligns with business objectives.
- Validate the business case and define measurable outcomes: Before proceeding further, it is crucial to validate the business case for the proposed solution. This involves assessing its feasibility, potential benefits, and alignment with strategic goals. Defining clear and measurable outcomes helps in evaluating project success.
- Map out the MVP end user experiences: To ensure user satisfaction and engagement, mapping out Minimum Viable Product (MVP) end-user experiences is essential. This involves identifying key touchpoints and interactions throughout the data life cycle stages. By considering user perspectives early on, organizations can create intuitive and effective solutions.
- Understand the data requirements: A thorough understanding of data requirements is vital for successful implementation. It includes identifying what types of data are needed, their sources, formats, quality standards, security considerations, and any specific regulations or compliance requirements.
- Gather required capabilities with platform architects: Collaborating with platform architects helps gather insights into available capabilities within existing infrastructure or technology platforms. This step ensures compatibility between business requirements and technical capabilities while minimizing redundancies or unnecessary investments.
- Establish data management roles, responsibilities, and procedures: Defining clear roles and responsibilities within the organization’s data management team is critical for effective execution. Establishing procedures for data observability, stewardship practices, access controls, privacy policies ensures consistency in managing data throughout its life cycle.
By following these elements in the business requirements phase, organizations can lay a solid foundation for successful data management and optimize the overall data life cycle. It sets the stage for subsequent phases, including data acquisition, storage, processing, analysis, and utilization.
Build, Test, and Iterate the Solution
To successfully implement a data life cycle, it is crucial to focus on building, testing, and iterating the solution. This phase involves several key steps that ensure the development and deployment of a robust and efficient system.
- Plan development and deployment: The first step in this phase is to carefully plan the development and deployment process. This includes identifying the goals and objectives of the project, defining timelines and milestones, and allocating resources effectively. By having a clear plan in place, the data team can streamline their efforts towards achieving desired outcomes.
- Gather end-user feedback at every stage: Throughout the development process, it is essential to gather feedback from end users at every stage. This allows for iterative improvements based on real-world usage scenarios. By actively involving end users in providing feedback, the data team can identify areas for enhancement or potential issues that need to be addressed.
- Define CI/CD pipelines for fast testing and iteration: Implementing Continuous Integration (CI) and Continuous Deployment (CD) pipelines enables fast testing and iteration of the solution. These pipelines automate various stages of software development such as code integration, testing, deployment, and monitoring. By automating these processes, any changes or updates can be quickly tested and deployed without manual intervention.
- Data preparation, cleaning, and processing: Before training machine learning models or conducting experiments with datasets, it is crucial to prepare, clean, and process the data appropriately. This involves tasks such as removing outliers or missing values from datasets to ensure accurate results during model training.
- Feature engineering: Feature engineering plays a vital role in enhancing model performance by selecting relevant features from raw data or creating new features based on domain knowledge. It involves transforming raw data into meaningful representations that capture essential patterns or characteristics.
- Training and ML experiments: In this stage of the data life cycle, machine learning models are trained using appropriate algorithms on prepared datasets. Multiple experiments may be conducted, testing different algorithms or hyperparameters to find the best-performing model.
- Model deployment: Once a satisfactory model is obtained, it needs to be deployed in a production environment. This involves integrating the model into existing systems or creating new APIs for real-time predictions.
- Model monitoring and scoring: After deployment, continuous monitoring of the model’s performance is essential. Tracking key metrics and scoring the model’s outputs against ground truth data helps identify any degradation in performance or potential issues that require attention.
By following these steps and iterating on the solution based on user feedback, data teams can ensure an efficient and effective data life cycle from development to deployment and beyond.
Efficiently Scale and Drive Adoption with Your Operating Model
To efficiently scale your data life cycle and drive adoption, you need to focus on several key areas. Let’s dive into each of them:
- Deploy into production: Once you have built and tested your solution, it’s time to deploy it into production. This step involves moving your solution from a development environment to a live environment where end users can access and utilize it.
- Evaluate production results: After deploying your solution, it is crucial to evaluate its performance in the production environment. Monitor key metrics and gather feedback from users to identify any issues or areas for improvement.
- Socialize data observability and FinOps best practices: To ensure the success of your operating model, it is essential to socialize data observability and FinOps best practices among your team. This involves promoting transparency, accountability, and efficiency in managing data operations.
- Acknowledge engineers who “shift left” performance and efficiency: Recognize and reward engineers who prioritize performance and efficiency early in the development process. Encourage a culture of proactive optimization by acknowledging those who contribute to improving the overall effectiveness of the data life cycle.
- Manage access, incidents, support, and feature requests: Efficiently scaling your operating model requires effective management of access permissions, incident handling processes, support systems, and feature requests. Streamline these processes to ensure smooth operations while accommodating user needs.
- Track progress towards business outcomes by measuring and sharing KPIs: Measuring key performance indicators (KPIs) is vital for tracking progress towards business outcomes. Regularly measure relevant metrics related to adoption rates, user satisfaction levels, cost savings achieved through efficiency improvements, etc., then share this information across teams for increased visibility.
By implementing these strategies within your operating model, you can efficiently scale your data life cycle while driving adoption among users. Remember that continuous evaluation and improvement are critical for optimizing performance throughout the life cycle.
Stop wasting Databricks spend—act now with a free health check.
Drive for Performance with Purpose-Built AI
Unravel helps with many elements of the Databricks operating model:
- Quickly identify failed and inefficient Databricks jobs: One of the key challenges is identifying failed and inefficient Databricks jobs. However, with AI purpose-built for Databricks, this task becomes much easier. By leveraging advanced analytics and monitoring capabilities, you can quickly pinpoint any issues in your job executions.
- Creating ML models vs deploying them into production: Creating machine learning models is undoubtedly challenging, but deploying them into production is even harder. It requires careful consideration of factors like scalability, performance, and reliability. With purpose-built AI tools, you can streamline the deployment process by automating various tasks such as model versioning, containerization, and orchestration.
- Leverage Unravel’s Analysis tab for insights: To gain deeper insights into your application’s performance during job execution, leverage the analysis tab provided by purpose-built AI solutions. This feature allows you to examine critical details like memory usage errors or other bottlenecks that may be impacting job efficiency.
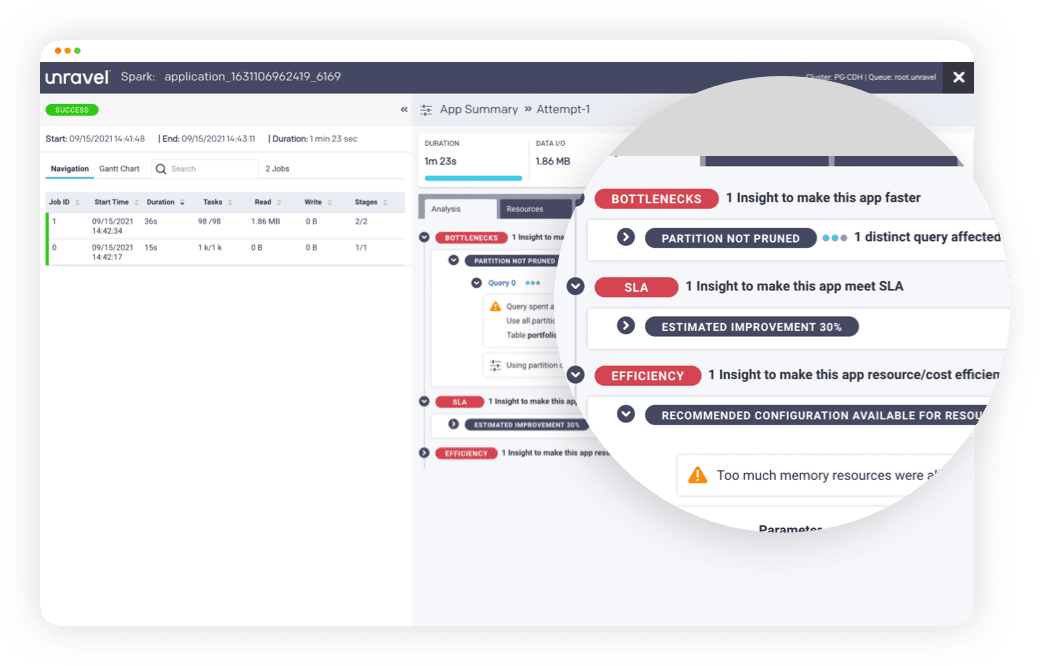

Unravel’s AI-powered analysis automatically provides deep, actionable insights.
- Share links for collaboration: Collaboration plays a crucial role in data management and infrastructure optimization. Unravel enables you to share links with data scientists, developers, and data engineers to provide detailed information about specific test runs or failed Databricks jobs. This promotes collaboration and facilitates a better understanding of why certain jobs may have failed.
- Cloud data cost management made easy: Cloud cost management, also known as FinOps, is another essential aspect of data life cycle management. Purpose-built AI solutions simplify this process by providing comprehensive insights into cost drivers within your Databricks environment. You can identify the biggest cost drivers such as users, clusters, jobs, and code segments that contribute significantly to cloud costs.
- AI recommendations for optimization: To optimize your data infrastructure further, purpose-built AI platforms offer valuable recommendations across various aspects, including infrastructure configuration, parallelism settings, handling data skewness issues, optimizing Python/SQL/Scala/Java code snippets, and more. These AI-driven recommendations help you make informed decisions to enhance performance and efficiency.
Learn More & Next Steps
Unravel hosted a virtual roundtable, Accelerate the Data Analytics Life Cycle, with a panel of Unravel and Databricks experts. Unravel VP Clinton Ford moderated the discussion with Sanjeev Mohan, principal at SanjMo and former VP at Gartner, Subramanian Iyer, Unravel training and enablement leader and Databricks SME, and Don Hilborn, Unravel Field CTO and former Databricks lead strategic solutions architect.
FAQs
How can I implement a scalable operating model for my data life cycle?
To implement a scalable operating model for your data life cycle, start by clearly defining roles and responsibilities within your organization. Establish efficient processes and workflows that enable seamless collaboration between different teams involved in managing the data life cycle. Leverage automation tools and technologies to streamline repetitive tasks and ensure consistency in data management practices.
What are some key considerations during the Business Requirements Phase?
During the Business Requirements Phase, it is crucial to engage stakeholders from various departments to gather comprehensive requirements. Clearly define project objectives, deliverables, timelines, and success criteria. Conduct thorough analysis of existing systems and processes to identify gaps or areas for improvement.
How can I drive adoption of my data life cycle operational model?
To drive adoption of your data management solution, focus on effective change management strategies. Communicate the benefits of the solution to all stakeholders involved and provide training programs or resources to help them understand its value. Encourage feedback from users throughout the implementation process and incorporate their suggestions to enhance usability and address any concerns.
What role does AI play in optimizing the data life cycle?
AI can play a significant role in optimizing the data life cycle by automating repetitive tasks, improving data quality through advanced analytics and machine learning algorithms, and providing valuable insights for decision-making. AI-powered tools can help identify patterns, trends, and anomalies in large datasets, enabling organizations to make data-driven decisions with greater accuracy and efficiency.
How do I ensure performance while implementing purpose-built AI?
To ensure performance while implementing purpose-built AI, it is essential to have a well-defined strategy. Start by clearly defining the problem you want to solve with AI and set measurable goals for success. Invest in high-quality training data to train your AI models effectively. Continuously monitor and evaluate the performance of your AI system, making necessary adjustments as needed.
Other Useful Links
- Our Databricks Optimization Platform
- Get a Free Databricks Health Check
- Check out other Databricks Resources