


Jeeves is the stereotypical English butler – and an AI chatbot that answers pertinent and important questions about Spark jobs in production. Shivnath Babu, CTO and co-founder of Unravel Data, spoke yesterday at Data + AI Summit, formerly known as Spark Summit, about the evolution of Jeeves, and how the technology has become a key supporting pillar within Unravel Data’s software.
Unravel is a leading platform for DataOps, bringing together a raft of seemingly disparate information to make it much easier to view, monitor, and manage pipelines. With Unravel, individual jobs and their pipelines become visible. But also, the interactions between jobs and pipelines become visible too.
It’s often these interactions, which are ephemeral, and very hard to track through traditional monitoring solutions, that cause jobs to cause or fail. Unravel makes them visible and actionable. On top of this, AI and machine learning help the software make proactive suggestions about improvements, and even head off trouble before it happens.
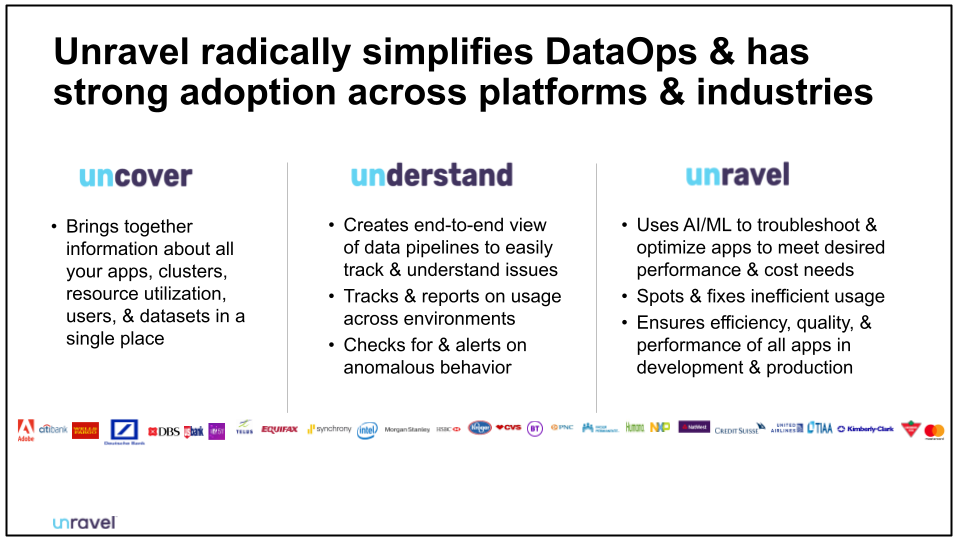
Both performance improvements and cost management become far easier with Unravel, even for DataOps personnel who don’t know all of the underlying technologies used by a given pipeline in detail.
Jeeves to the Rescue
An app failure in Spark may be difficult to even discover – let alone to trace, troubleshoot, repair, and retry. If the failure is due to interactions among multiple apps, a whole additional dimension of trouble arises. As data volumes and pipeline criticality rocket upward, no one in a busy IT department has time to dig around for the causes of problems and search for possible solutions.

But – Jeeves to the rescue! Jeeves acts as a chatbot for finding, understanding, fixing, and improving Spark jobs, and the configuration settings that define where, when, and how they run. The Jeeves demo in Shivnath’s talk shows how Jeeves comes up with the errant Spark job (by ID number), describes what happened, and recommends the needed adjustments – configuration changes, in this case – to fix the problem going forward. Jeeves can even resubmit the repaired job for you.
See how Unravel simplifies troubleshooting Spark
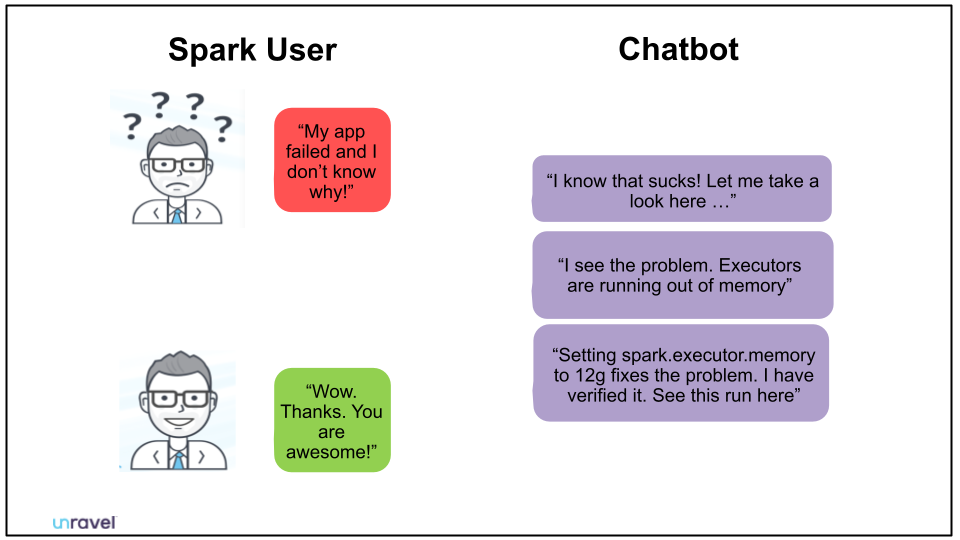
Wait, One More Thing…
But there’s more – much more. The technology underlying Jeeves has now been built into Unravel Data, with stellar results.
Modern data pipelines are ever more populated. In his talk, Shivnath shows us several views on the modern data landscape. His simplified diagram shows five silos, and 14 different top-level processes, between today’s data sources and a plethora of data consumers, both human and machine.
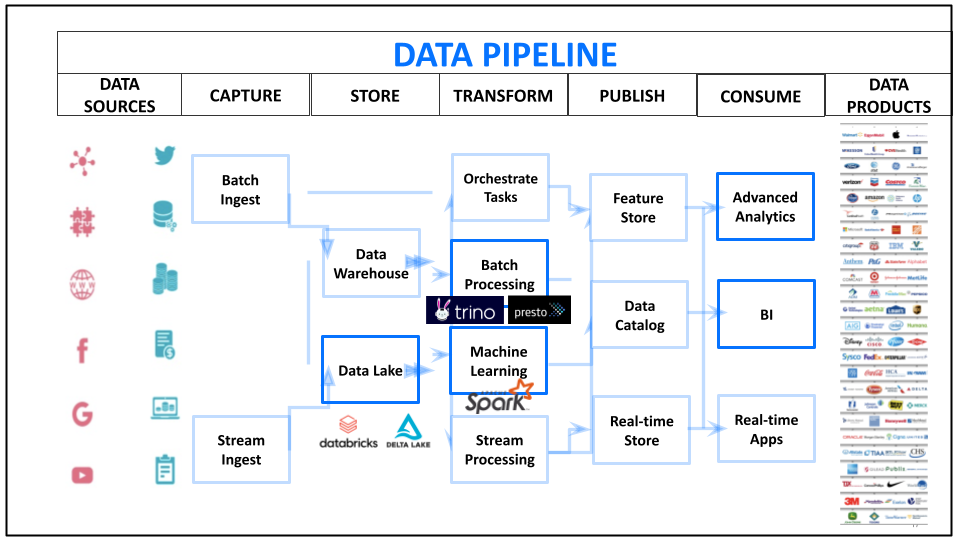
But Shivnath shines a bright light into this Aladdin’s cave of – well, either treasures or disasters, depending on your point of view, and whether everything is working or not. He describes each of the major processes that take place within the architecture, and highlights the plethora of technologies and products that are used to complete each process.
He sums it all up by showing the role of data pipelines in carrying out mission-critical tasks, how the data stack for all of this continues to get more complex, and how DataOps as a practice has emerged to try and get a handle on all of it.
This is where we move from Jeeves, a sophisticated bot, to Unravel, which incorporates the Jeeves functionality – and much more. Shivnath describes Unravel’s Pipeline Observer, which interacts with a large and growing range of pipeline technologies to monitor, manage, and recommend (through an AI and machine learning-powered engine) how to fix, improve, and optimize pipeline and workload functionality and reliability.
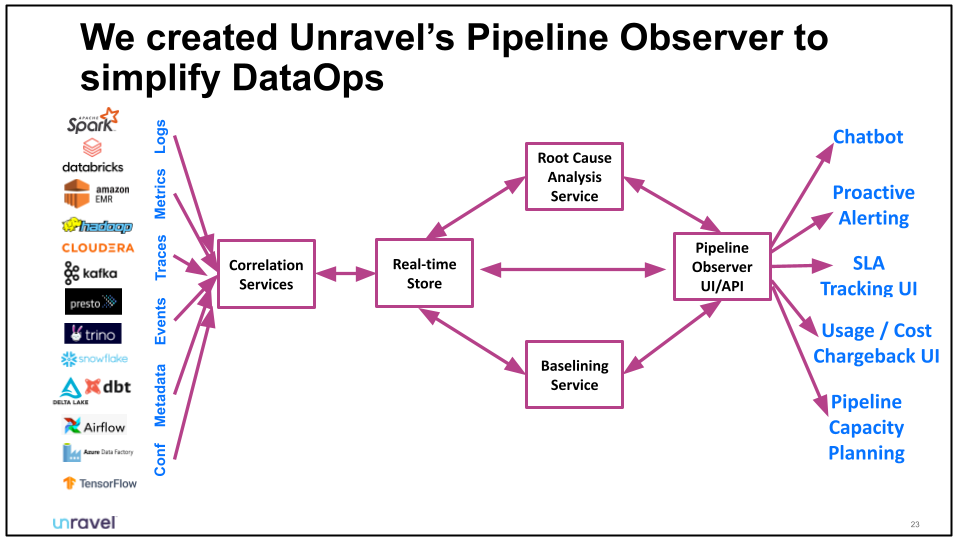
In an Unravel demo, Shivnath shows how to improve a pipeline that’s in danger of:
- Breaking due to data quality problems
- Missing its performance SLA
- Cost overruns – check your latest cloud bill for examples of this one
If you’re in DataOps, you’ve undoubtedly experienced the pain of pipeline breaks, and that uneasy feeling of SLA misses, all reflected in your messaging apps, email, and performance reviews – not to mention the dreaded cost overruns, which don’t show up until you look at your cloud provider bills.
Shivnath concludes by offering a chance for you to create a free account; to contact the company for more information; or to reach out to Shivnath personally, especially if your career is headed in the direction of helping solve these and related problems. To get the full benefit of Shivnath’s perspective, dig into the context, and understand what’s happening in depth, please watch the presentation.