

Table of Contents
One of the world’s largest logistics companies leverages automation and AI to empower every individual data engineer with self-service capability to optimize their jobs for performance and cost. The company was able to cut its cloud data costs by 70% in six months—and keep them down with automated 360° cost visibility, prescriptive guidance, and guardrails for its 3,000 data engineers across the globe. The company pegs the ROI of Unravel at 20X: “for every $1 we invested, we save 20.”
Key Results
- 20X ROI from Unravel
- cut costs by 70% in 6 months
- 75% time savings via automation
- proactive guardrails to keep costs within budgets
- automated AI health checks in CI/CD prevent inefficiencies in production
Holding individuals accountable for cloud usage/cost
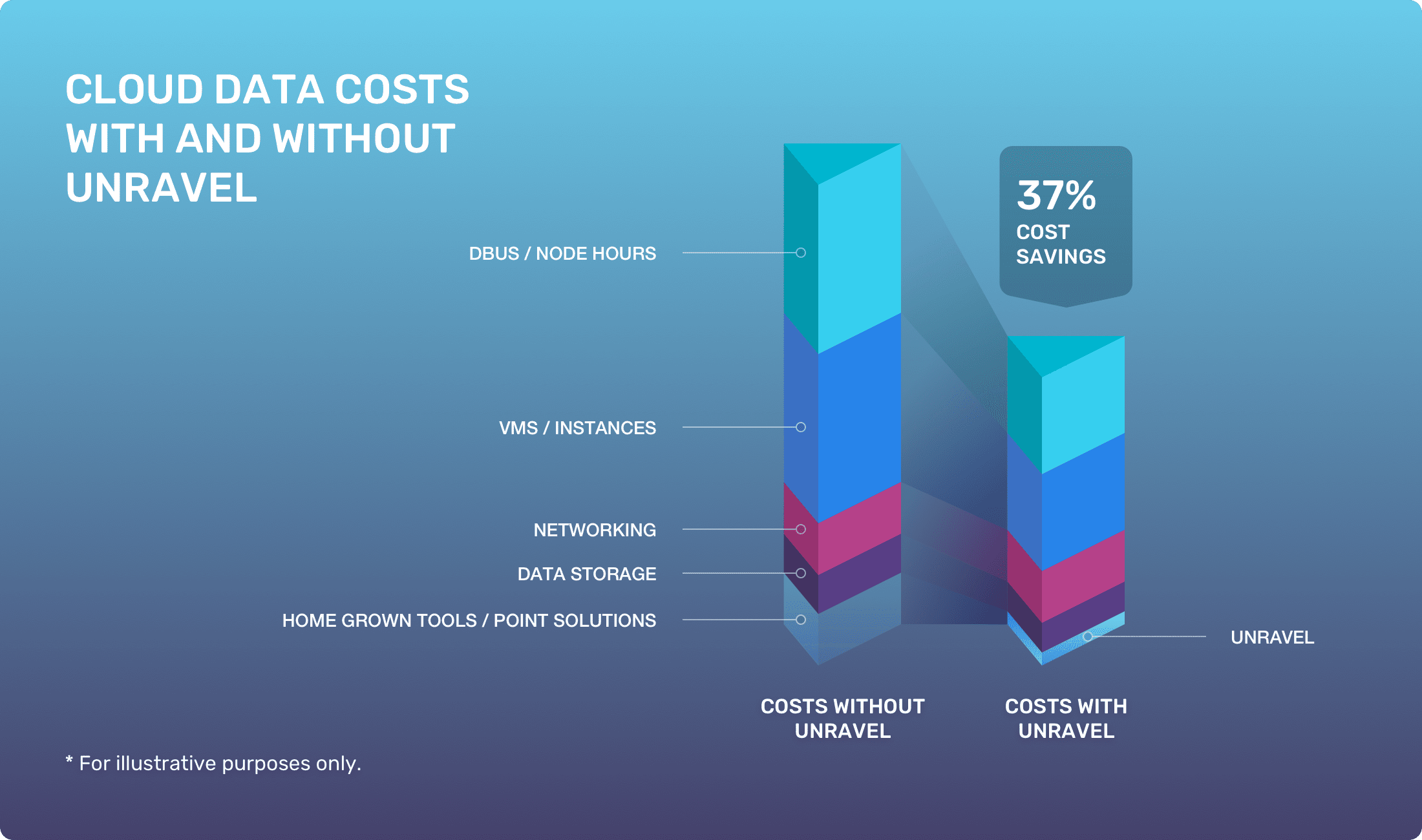
Like many organizations moving their data workloads to the cloud, the company soon found that its cloud data costs were very rapidly rising to unacceptable levels. Data analytics are core to the business, but the cost of its cloud data workloads was simply getting too unpredictable and expensive. Cloud data expenses had to be brought under control.
The company chose Unravel to enable a shift-left approach where data engineers become more aware and individually accountable for their cloud usage/spending, and are given the means to make better, more cost-effective decisions when incurring expenses.
Data is core to the business
The company is increasingly doing more things with more data for more reasons. Says its Head of Data Platform Optimization, “Data is pervasive in logistics. Data is literally at the center of pretty much everything [we do]. Picking up goods to transport them, following the journeys of those goods, making all the details of those journeys available to customers. Our E Class ships can take 18,000 shipping containers on one journey from, say, China to Europe. One journey on one of those ships moves more goods than was moved in the entire 19th century between continents. One journey. And we’ve got six of them going back and forth all the time.”

But the company also uses data to drive innovation in integrated logistics, supply chain resiliency, and corporate social responsibility. “[We’re] a company that doesn’t just use data to figure out how to make money, we use data to better the company, make us more profitable, and at the same time put back into the planet.
“The data has risen exponentially, and we’re just starting to come to grips with what we can do with it. For example, in tandem with a couple of nature organizations, we worked out that if a ship hits a whale at 12 knots and above, that whale will largely die. Below 12 knots, it will live. We used the data about where the whales were to slow the ships down.”
Getting visibility into cloud data costs
The single biggest obstacle to controlling cloud costs for any data-forward organization is having only hazy visibility into cloud usage. The company saw its escalating cloud data platform costs as an efficiency issue—how efficiently the company’s 3,000 “relatively young and inexperienced” data engineers were running their jobs.
Says the company’s Head of Data Platform Optimization, “We’ve been moving into the cloud over the past 3-4 years. Everybody knows that [the] cloud isn’t free. There’s not a lot of altruism there from the cloud providers. So that’s the biggest issue we faced. We spent 12 months deploying a leading cloud data platform, and at the end of 12 months, the platform was working fine but the costs were escalating.
“The problem with that is, if you don’t have visibility on those costs, you can’t cut those costs. And everybody—no matter what your financial situation—wants to cut costs and keep them down. We had to attain [cost] visibility. Unravel gives us the visibility, the insight, to solve that problem.”
“The [cloud data] platform was working fine but the costs were escalating. If you don’t have visibility on those costs, you can’t cut those costs.”
Get costs right in Dev, before going into production
The logistics company emphasizes that you have to get it right for cost and performance up front, in development. “Don’t ever end up with a cost problem. That’s part of the [shifting] mindset. Get in there early to deal with cost. Go live with fully costed jobs. Don’t go live and then work out what the job cost is and figure out how to cut it. [Determine] what it’s going to cost in Dev/Test, what it’s going to cost in Prod, then check it as soon as it goes live. If the delta’s right, game on.”
As the company’s data platform optimization leader points out, “Anybody can spin up a cloud environment.” Quite often their code and resource configurations are not optimized. Individual engineers may be requesting oversized resources (size, number, type) than what they actually need to run their jobs successfully, or they have code issues that are leading to inefficient performance—and jobs costing more than they need to.
“The way to deal with this [escalating cost] problem is to push it left. Don’t have somebody charging in from Finance waving a giant bill saying, ‘You’re costing a fortune.’ Let’s keep Finance out of the picture. And crucial to this is: Do it up front. Do it in your Dev environment. Don’t go into production, get a giant bill, and only then try to figure out how to cut that.”
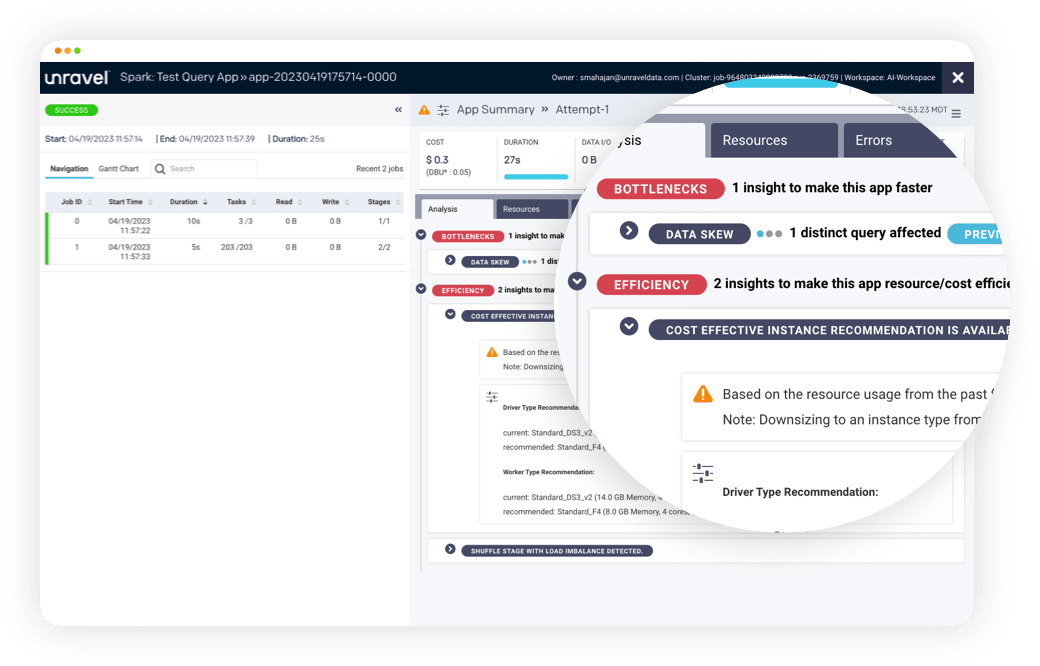
Unravel AI automatically identifies inefficient code, oversized resources, data partitioning problems, and other issues that lead to higher-than-necessary cloud data costs.
“One of the big problems with optimizing jobs is the sheer scale of what we’re talking about. We have anywhere between 5,000-7,500 data pipelines. You’re not just looking for a needle in a haystack . . . first of all, you have to find the haystack. Then you have to learn how to dig into it. That’s an awful lot of code for human beings to look at, something that machines are perfectly suited to. And Unravel is the best implementation we’ve seen of its kind.”
The Unravel platform harnesses full-stack visibility, contextual awareness, AI-powered actionable intelligence, and automation to go “beyond observability”—to not only show you what’s going on and why, but guide you with crisp, prescriptive recommendations on exactly how to make things better and then keep them that way proactively. (See the Unravel platform overview page for more detail.)
“We put Unravel right in the front of our development environment. So nothing goes into production unless we know it’s going to work at the right cost/price. We make sure problems never reach production. We cut them off at the pass, so to speak. Because otherwise, you’ve just invented the world’s best mechanism for closing the stable door after the cost horse has bolted.”
Empower self-service via immediate feedback loops
The company used to outsource a huge amount of its data workloads but is now moving to become an open source–first, built-in-house company. A key part of the company’s strategy is to enable strong engineering practices, design tenets (of which cost is one), and culture. For data platform optimization, that means empowering every data engineer with the insights, guidance, and guardrails to optimize their code so that workloads run highly efficiently and cost is not an afterthought.
“We’ve got approximately 3,000 people churning out Spark code. In a ‘normal environment,’ you can ask the people sitting next to you how they’d do something. We’ve had thousands of engineers working from home for the past two years. So how do you harvest that group knowledge and how do people learn?
“We put Unravel in to look at and analyze every single line of code written, and come up with those micro-suggestions—and indeed macro-suggestions—that you’d miss. We’ve been through everything like code walk-throughs, code dives, all those things that are standard practice. But if you have a couple of thousand engineers writing, say, 10 lines of code a day, you’ll never be able to walk through all that code.”
That’s where Unravel’s high degree of automation and AI really help. Unravel auto-discovers and captures metadata from every platform, system, and application across the company’s data stack, correlates it all into a meaningful workload-aware context, and automatically analyzes everything to pinpoint inefficiencies and offer up AI-powered recommendations to guide engineers on how to optimize their jobs.
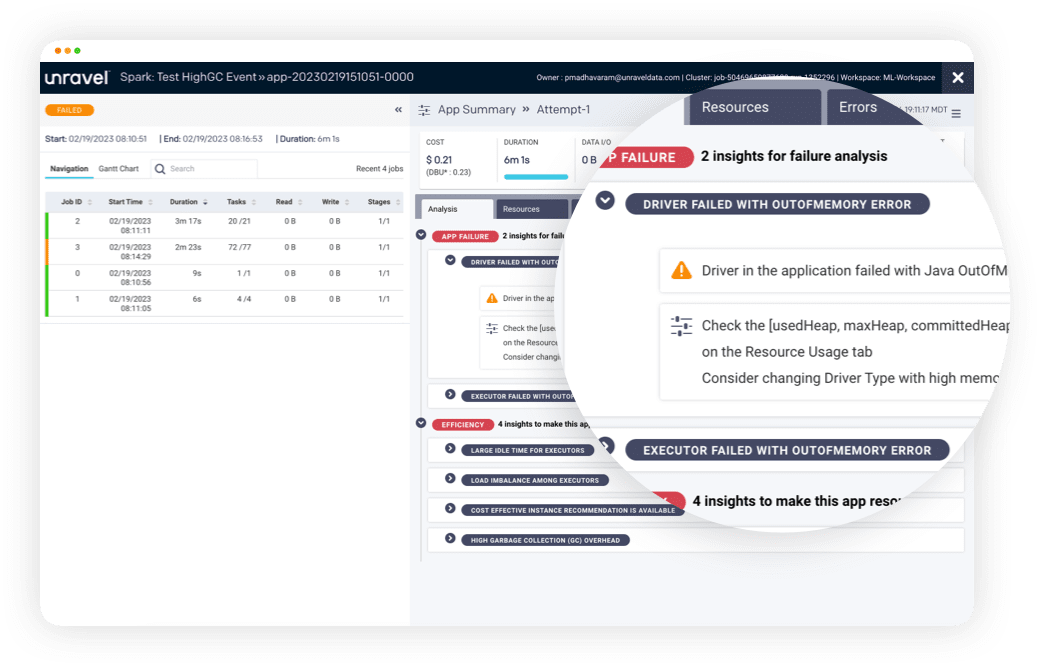
“We put Unravel right in the front of our development environment to look at and analyze every single line of code written and come up with suggestions [to improve efficiency].”
“Data engineers hate fixing live problems. Because it’s boring! And they want to be doing the exciting stuff, keep developing, innovating. So if we can stop those problems at Dev time, make sure they deploy optimal code, it’s a win-win. They never have to fix that production code, and honestly we don’t have to ask them to fix it.”
The company leverages Unravel’s automated AI analysis to up-level its thousands of developers and engineers worldwide. Optimizing today’s complex data applications/pipelines—for performance, reliability, and cost—requires a deeper level of data engineering.
“Because Unravel takes data from lots of other organizations, we’re harvesting the benefits of hundreds of thousands of coders and data engineers globally. We’re gaining the insights we couldn’t possibly get by being even the best at self-analysis.
“The key for me is to be able to go back to an individual data engineer and say, ‘Did you realize that if you did your code this way, you’d be 10 times more efficient?’ And it’s about giving them feedback that allows them to learn themselves. What I love about Unravel is that you get the feedback, but it’s not like they’re getting pulled into an office and having ‘a talk’ about those lines of code. You go into your private workspace, [Unravel] gives you the suggestions, you deal with the suggestions, you learn, you move on and don’t make the mistakes again. And they might not even be mistakes; they might just be things you didn’t know about. What we’re finding with Unravel is that it’s sometimes the nuances that pop up that give you the benefits. It’s pivotal to how we’re going to get the benefits, long term, out of what we’re doing.”
Efficiency improvements cut cloud data costs by 70%
The company saw almost immediate business value from Unravel’s automated AI-powered analysis and recommendations. “We were up and running within 48 hours. Superb professional services from Unravel, and a really willing team of people from our side. It’s a good mix.
The company needed to get cloud data costs under control—fast. More and more mission-critical data workloads were being developed on a near-constant cadence, and these massive jobs were becoming increasingly expensive. Unravel enabled the company to get ahead of its cloud data costs at speed and scale, saving millions.

“We started in the summer, and by the time Christmas came around, we had cut in excess of 70% of our costs. I’d put the ROI of Unravel at about 20X: every $1 we invested, we save $20.”
The company has been able to put into individual developers’ and engineers’ hands a tool to make smarter, data-driven decisions about how they incur cloud data expenses.
“What I say to new data engineers is that we will empower them to create the best systems in the world, but only you can empower yourself to make them the most efficient systems in the world. Getting data engineers to actually use Unravel was not a difficult task. We’re very lucky: people on our team are highly motivated to do the right thing—by the company, by themselves. If doing the right thing becomes the default option, people will follow that path.
“Unravel makes it easy to do the right thing.”