

Table of Contents
What is a Data Pipeline?
Data pipelines convert rich, varied, and high-volume data sources into insights that power the innovative data products that many of us run today. Shivnath represents a typical data pipeline using the diagram below.
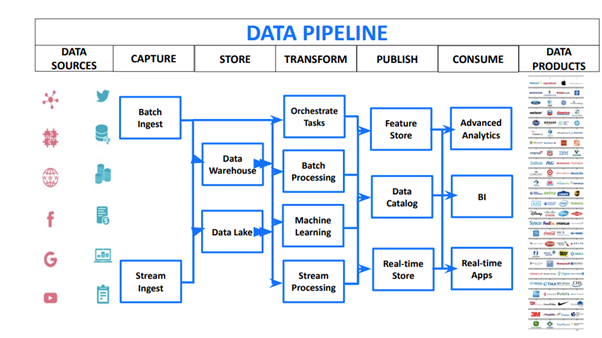
In a data pipeline, data is continuously captured and then stored into distributed a storage system, such as a data lake or data warehouse. From there, a lot of computation happens on the data to transform it into the key insights that you want to extract. These insights are then published and made available for consumption.
Modernizing Data Stacks and Pipelines
Many enterprises have already built data pipelines on stacks such as Hadoop, or using solutions such as NewHive and HDFS. Many of these pipelines are orchestrated with enterprise schedulers, such as Autosys, Tidal, Informatica Pentaho, or native schedulers. For example, Hadoop comes with a native scheduler called Oozie.
In these environments, there are common challenges people face when it comes to their data pipelines. These problems include:
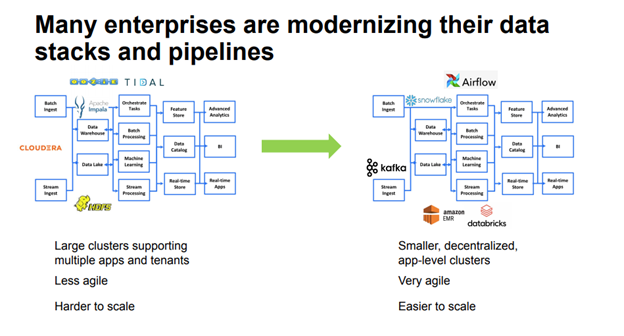
- Large clusters supporting multiple apps and tenants: Clusters tend to be heavily multi-tenant and some apps may struggle for resources.
- Less agility: In these traditional environments, there tends to be less agility in terms of adding more capabilities and releasing apps quickly.
- Harder to scale: In these environments, data pipelines tend to be in large data centers where you may not be able to add resources easily.
These challenges are causing many enterprises to modernize their stacks. In the process, they are picking innovative schedulers, such as Airflow, and they’re changing their stacks to incorporate systems like Databricks, Snowflake, or Amazon EMR. With modernization, companies are often striving for:
- Smaller, decentralized, app-focused clusters: Instead of running large clusters, companies are trying to run smaller, more focused environments.
- More agility and easier scalability: When clusters are smaller, they also tend to be more agile and easier to scale. This is because you can decouple storage from compute, then allocate resources when you need them.
Shivnath shares even more goals of modernization, including removing resources as a constraint when it comes to how fast you can release apps and drive ROI, as well as reducing cost.
So why does Airflow often get picked as part of modernization? The goals that motivated the creation of Airflow often tie in very nicely with the goals of modernization efforts. Airflow enables agile development and is better for cloud-native architectures compared to traditional schedulers, especially in terms of how fast you can customize or extend it. Keeping with the modern methodology of agility, Airflow is also available as a service from companies like Amazon and Astronomer.
Diving deeper into the process of modernization, there are two main phases at the high level, Phase 1: Assess and Plan and Phase 2: Migrate, Validate, and Optimize. The rest of the presentation dived deep into the key lessons that Shivnath and Hari have learned from helping a large number of enterprises migrate from their traditional enterprise schedulers and stacks to Airflow and modern data stacks.
Lessons Learned
Phase 1: Assess and Plan
The assessment and planning phase of modernization is made up of a series of other phases, including:
- Pipeline discovery: First you have to discover all the pipelines that need to be migrated.
- Resource usage analysis: You have to understand the resource usage of the pipelines.
- Dependency analysis: More importantly, you have to understand all the dependencies that the pipelines may have.
- Complexity analysis: You need to understand the complexity of modernizing the pipelines. For example, some pipelines that run on-prem can actually have thousands of stages and run for many hours.
- Mapping to the target environment.
- Cost estimation for target environment.
- Migration effort estimation.
Shivnath said that he has learned two main lessons from the assessment and planning phase:
Lesson 1: Don’t underestimate the complexity of pipeline discovery
Multiple schedulers may be used, such as Autosys, Informatica, Oozie, Pentaho, Tidal, etc. And worse, there may not be any common pattern in how these pipelines work, access data, schedule and name apps, or allocate resources.
Lesson 2: You need very fine grain tracking from a telemetry data perspective
Due to the complexity of data pipeline discovery, tracking is needed in order to do a good job at resource usage estimation, dependency analysis, and to map the complexity and cost of running pipelines in a newer environment.
After describing the two lessons, Shivnath goes through an example to further illustrate what he has learned.
Shivnath then passes it on to Hari, who speaks about the lessons learned during the migration, validation, and optimization phase of modernization.
Phase 2: Migrate, Validate, and Optimize
While Shivnath shared various methodologies that have to do with finding artifacts and discovering the dependencies between them, there is also a need to instill a sense of confidence in the entire migration process. This confidence can be achieved by validating the operational side of the migration journey.
Data pipelines, regardless of where they live, are prone to suffer from the same issues, such as:
- Failures and inconsistent results
- Missed SLAs and growing lag/backlog
- Cost overruns (especially prevalent in the cloud)
To maintain the overall quality of your data pipelines, Hari recommends constantly evaluating pipelines using three major factors: correctness, performance, and cost. Here’s a deeper look into each of these factors:
- Correctness: This refers to data quality. Artifacts such as tables, views, or CSV files are generated at almost every stage of the pipeline. We need to lay down the right data checks at these stages, so that we can make sure that things are consistent across the board. For example, a check could be that the partitions of a table should have at least n number of records. Another check could be that a specific column of a table should never have null values.
- Performance: Evaluating performance has to do with setting SLAs and maintaining baselines for your pipeline to ensure that performance needs are met after the migration. Most orchestrators have SLA monitoring baked in. For example, in Airflow the notion of an SLA is incorporated in the operator itself. Additionally, if your resource allocations have been properly estimated during the migration assessment and planning phase, often you’ll see that SLAs are similar and maintained. But in a case where something unexpected arises, tools like Unravel can help maintain baselines, and help troubleshoot and tune pipelines, by identifying bottlenecks and suggesting performance improvements.
- Cost: When planning migration, one of the most important parts is estimating the cost that the pipelines will incur and, in many cases, budgeting for it. Unravel can actually help monitor the cost in the cloud. And by collecting telemetry data and interfacing with cloud vendors, Unravel can offer vendor-specific insights that can help minimize the running cost of these pipelines in the cloud.
Hari then demos several use cases where he can apply the lessons learned. To set the stage, a lot of Unravel’s enterprise customers are migrating from the more traditional on-prem pipelines, such as Oozie and Tidal, to Airflow. The examples in this demo are actually motivated by real scenarios that customers have faced in their migration journey.