

DBTA recently hosted a roundtable webinar with four industry experts on “Unlocking the Value of Cloud Data and Analytics.” Moderated by Stephen Faig, Research Director, Unisphere Research and DBTA, the webinar featured presentations from Progress, Ahana, Reltio, and Unravel.
You can see the full 1-hour webinar “Unlocking the Value of Cloud Data and Analytics” below.

Here’s a quick recap of what each presentation covered.
Todd Wright, Global Product Marketing Manager at Progress, in his talk “More Data Makes for Better Analytics” showed how Progress DataDirect connectors let users get to their data from more sources securely without adding a complex software stack in between. He quoted former Google research director Peter Norvig (now fellow at the Stanford Institute for Human-Centered Artificial Intelligence) about how more data beats clever algorithms: “Simple models and a lot of data trump more elaborate models based on less data.” He then outlined how Progress DataDirect and its Hybrid Data Pipeline platform uses standard-based connectors to expand connectivity options of BI and analytics tools, access all your data using a single connector, and make on-prem data available to cloud BI and analytics tools without exposing ports or implementing costly and complex VPN tunnels. He also addressed how to secure all data sources behind your corporate authentication/identity to mitigate the risk of exposing sensitive private information (e.g., which tables and columns to expose to which people) and keep tabs on data usage for auditing and compliance.
Rachel Pedreschi, VP of Technical Services at Ahana, presented “4 Easy Tricks to Save Big Money on Big Data in the Cloud.” She first simplified the cloud data warehouse into its component parts (data on disk + some kind of metadata + a query layer + system that authenticates users and allows them to do stuff). Then she broke it down to see where you could save some money. Starting at the bottom, the storage layer, she said data lakes are a more cost-effective way of providing data to users throughout the organization. At the metadata level, Hive Metastore or AWS Glue are less expensive options. For authentication, she mentioned Apache Ranger or AWS Lake Formation. But what about SQL? For that she has Presto, an open source project that came out of Facebook as a successor to Hive. Presto is a massively scalable distributed in-memory system that allows you write queries not just against data lake files but also other databases as well. She calls this collectively the Open SQL Data Lakehouse. Ahana is an AWS-based service that gets you up and running with this Open Data Lakehouse in 30 minutes.
Download the white paper
Mike Frasca, Field Chief Field Technology Officer at Reltio, discussed the value and benefits of a modern master data management platform. He echoed previous presenters’ points about how the volume, velocity, and variety of data have become almost overwhelming, especially given how highly siloed and fragmented data is today. Data teams spend most of their time getting the data ready for insights—data consolidation, aggregation, and cleansing; synchronizing and standardizing data, ensuring data quality, timeliness, and accuracy, etc.—rather than actually delivering insights from analytics. He outlined the critical functions a master data management (MDM) platform should provide to deliver precision data. Entity management automatically unifies data into a dynamic enterprise source of truth, including context-aware master records. Data quality management continuously validates, cleans, and standardizes the data via custom validation rules. Data integration receives input from and distributes mastered data to any application or data store in real time and at high volumes. He emphasized that what characterizes a “modern” MDM is the ability to access data in real time—so you’re not making decisions based on data that’s a week or a month old. Cloud MDM extends the capabilities to relationship management, data governance, and reference data management. He wound up his presentation with compelling real-life examples of customer efficiency gains and effectiveness, including Forrester TEI (total economic impact) results on ROI.
Chris Santaigo, VP of Solutions Engineering at Unravel, presented how AI-enabled optimization and automatic insights help unlock the value of cloud data. He noted how nowadays every company is a data company. If they’re not leveraging data analytics to create strategic business advantages, they’re falling behind. But he illustrated how the complexity of the modern data stack is slowing companies down. He broke down the challenges into three C’s: cost, where enterprises are experiencing significant budget overruns; resource constraints—not infrastructure resources, but human resources—the talent gap and mismatch between supply and demand for expertise; and complexity of the stack, where 87% of data science projects never make it into production because it’s so challenging to implement them.
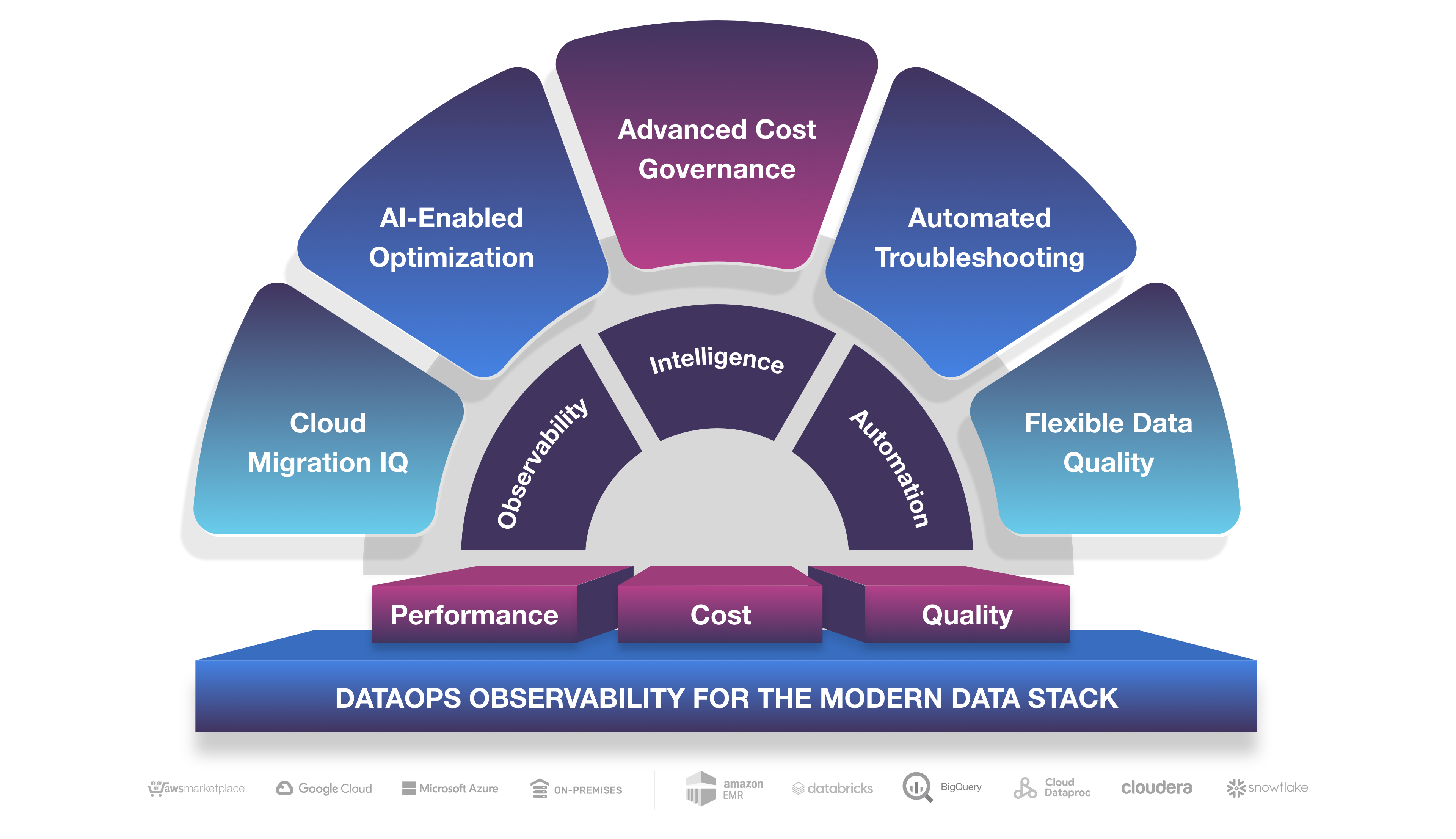
But it all comes down to people—all the different roles on data teams. Analysts, data scientists, engineers on the application side; architects, operations teams, FinOps, and business stakeholders on the operations side. Everybody needs to be working off a “single source of truth” to break down silos, enable collaboration, eliminate finger-pointing, and empower more self-service. Software teams have APM to untangle this complexity—for web apps. But data apps are a totally different beast. You need observability designed specifically for data teams. You could try to stitch together the details you need for performance, cost, data quality from a smorgasbord of point tools or solutions that do some of what you need (but not all), but that’s time-consuming and misses the holistic view of how everything works together so necessary to connect the dots when you’re looking to troubleshoot faster, control spiraling cloud costs, automate AI-driven optimization (for performance and cost), or migrate to the cloud on budget and on time. That’s exactly where Unravel comes in.
Check out the full webinar, including attendee Q&A here!