

Table of Contents
At the recent Data Summit 2022 conference in Boston, Unravel presented “The DataOps Journey: Beyond Observability”—the most highly attended session within the conference’s DataOps Boot Camp track. In a nutshell, Unravel VPs Keith Alsheimer and Chris Santiago discussed:
- The top challenges facing different types of data teams today
- Why web APM and point tools leave fundamentally big observability gaps
- How observability purpose-built for the modern data stack closes these gaps
- What going “beyond observability” looks like
Data teams get caught in a 4-way crossfire
It’s been said many times, many ways, but it’s true: nowadays every company has become a data company. Data pipelines are creating strategic business advantages, and companies are depending on their data pipelines more than ever before. And everybody wants in—every department in every business unit in every kind of company wants to leverage the insights and opportunities of big data.

But data teams are finding themselves caught in a 4-way crossfire: not only are data pipelines more important than ever, but more people are demanding more output from them, there’s more data to process, people want their data faster, and the modern data stack has gotten ever more complex.
The increased volume, velocity, and variety of today’s data pipelines coupled with their increasing complexity is leaving battle scars across all teams. Data engineers find it harder to troubleshoot apps/pipelines, meet SLAs, and get quality right. Operations teams have too many issues to solve and not enough time—they’re drowning in a flood of service tickets. Data architects have to figure out how to scale these complex pipelines efficiently. Business unit leaders are seeing cloud costs skyrocket and are under the gun to deliver better ROI.
Unlock your data environment health with a free health check.
It’s becoming increasingly harder for data teams to keep pace, much less do everything faster, better, cheaper. All this complexity is taking its toll. Data teams are bogged down and burning out. A recent survey shows that 70% of data engineers are likely to quit in the next 12 months. Demand for talent has always exceeded supply, and it’s getting worse. McKinsey research reveals that data analytics has the greatest need to address potential skills gaps, with 15 open jobs for every active job seeker. The latest LinkedIn Emerging Jobs Report says that 5 of the top 10 jobs most in demand are data-related.
And complexity continues in the cloud. First off, the variety of choices is huge—with more coming every day. Too often everybody is doing their own thing in the cloud, with no clear sense of what’s going on. This makes things hard to rein in and scale out, and most companies find their cloud costs are getting out of control.
DataOps is the answer, but . . .
Adopting a DataOps approach can help solve these challenges. There are varying viewpoints on exactly what DataOps is (and isn’t), but we can certainly learn from how software developers and operations teams tackled a similar issue via DevOps—specifically, leveraging and enhancing collaboration, automation, and continuous improvement.
One of the key foundational needs for this approach is observability. You absolutely must have a good handle on what’s going on in your system, and why. After all, you can’t improve things—much less simplify and streamline—if you don’t really know everything that’s happening. And you can’t break down silos and embrace collaboration without the ability to share information.
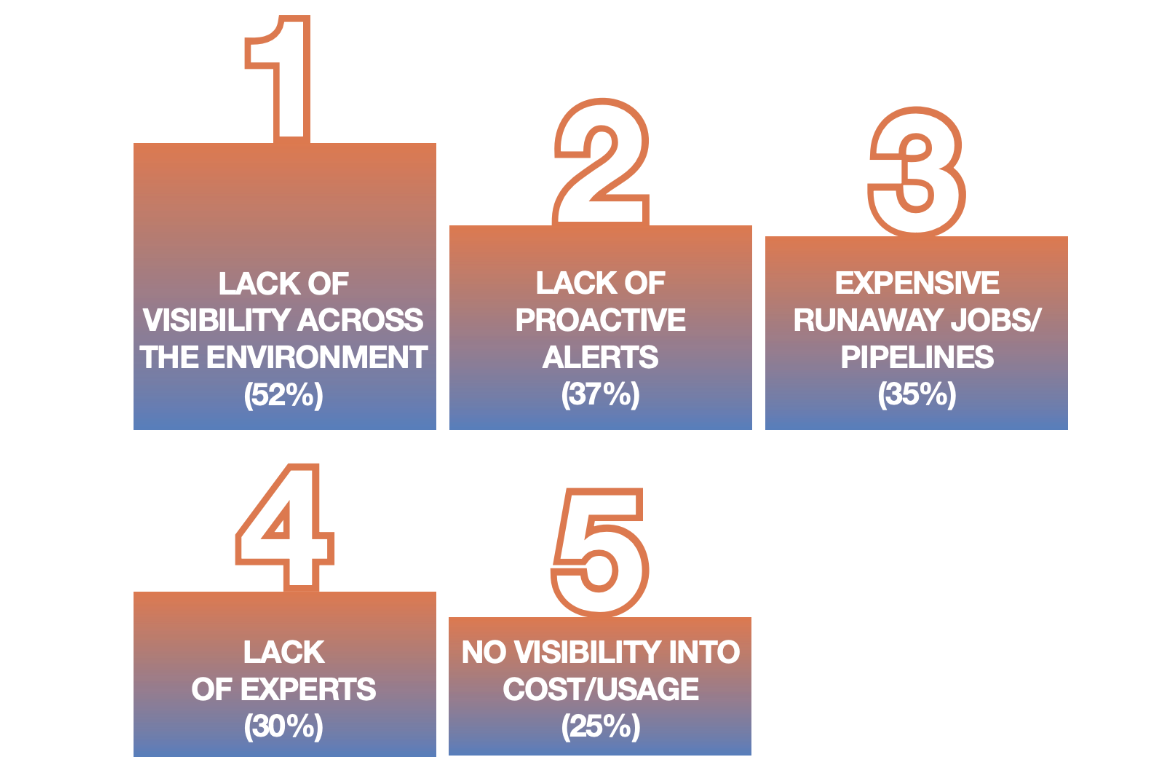
At DataOps Unleashed 2022 we surveyed some 2,000 participants about their top challenges, and by far the #1 issue was the lack of visibility across the environment (followed by lack of proactive alerts, the expense of runaway jobs/pipelines, lack of experts, and no visibility into cloud cost/usage).
One of the reasons teams have so much difficulty gaining visibility into their data estate is that the kind of observability that works great for DevOps doesn’t cut it for DataOps. You need observability purpose-built for the modern data stack.
Get the right kind of observability
When it comes to the modern data stack, traditional observability tools leave a “capabilities gap.” Some of the details you need live in places like the Spark UI, other information can be found in native cloud tools or other point solutions, but all too often you have to jump from tool to tool, stitching together disparate data by yourself manually. Application performance monitoring (APM) does this correlation for web applications, but falls far short for data applications/pipelines.
First and foremost, the whole computing framework is different for data applications. Data workloads get broken down into multiple, smaller, often similar parts each processed concurrently on a separate node, with the results re-combined upon completion — parallel processing. In contrast, web applications are a tangle of discrete request-response services processed individually.

Consequently, there’s a totally different class of problems, root causes, and remediation for data apps vs. web apps. When doing your detective work into a slow or failed app, you’re looking at a different kind of culprit for a different type of crime, and need different clues. You need a whole new set of data points, different KPIs, from distinct technologies, visualized in another way, and correlated in a uniquely modern data stack–specific context.
You need to see details at a highly granular level — for each sub-task within each sub-part of each job — and then marry them together into a single pane of glass that comprises the bigger picture at the application, pipeline, platform, and cluster levels.
That’s where Unravel comes in.
Unravel extracts all the relevant raw data from all the various components of your data stack and correlates it to paint a picture of what’s happening. All the information captured by telemetry data (logs, metrics, events, traces) is pulled together in context and in the “language you’re speaking”—the language of data applications and pipelines—within the context of your workloads.
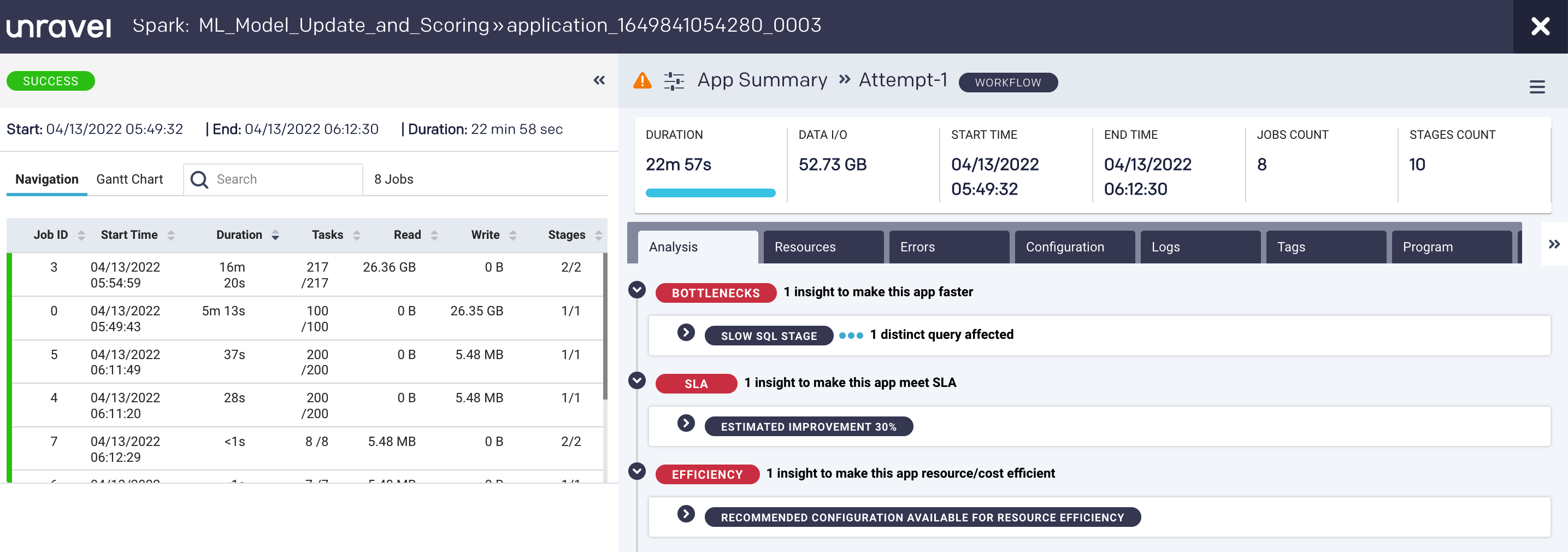
click to enlarge
Going beyond observability
Full-stack observability tells you what’s going on. But to understand why, you need to go beyond observability and apply AI/ML to correlate patterns, identify anomalies, derive meaningful insights, and perform automated root cause analysis. And for that, you need lots of granular data feeding ML models and AI algorithms purpose-built specifically for modern data apps/pipelines.
The size and complexity of modern data pipelines—with hundreds (even thousands) of intricate interdependencies, jobs broken down into stages processing in parallel—could lead to a lot of trial-and-error resolution effort even if you know what’s happening and why. What you really need to know is what to do.
That’s where Unravel goes where other observability solutions can only dream about.
Unravel’s AI recommendation engine tells you exactly what your next step is in crisp, precise detail. For example, if there’s one container in one part of one job that’s improperly sized and so causing the entire pipeline to fail, Unravel not only pinpoints the guilty party but tells you what the proper configuration settings would be. Or another example is that Unravel can tell you exactly why a pipeline is slow and how you can speed it up.
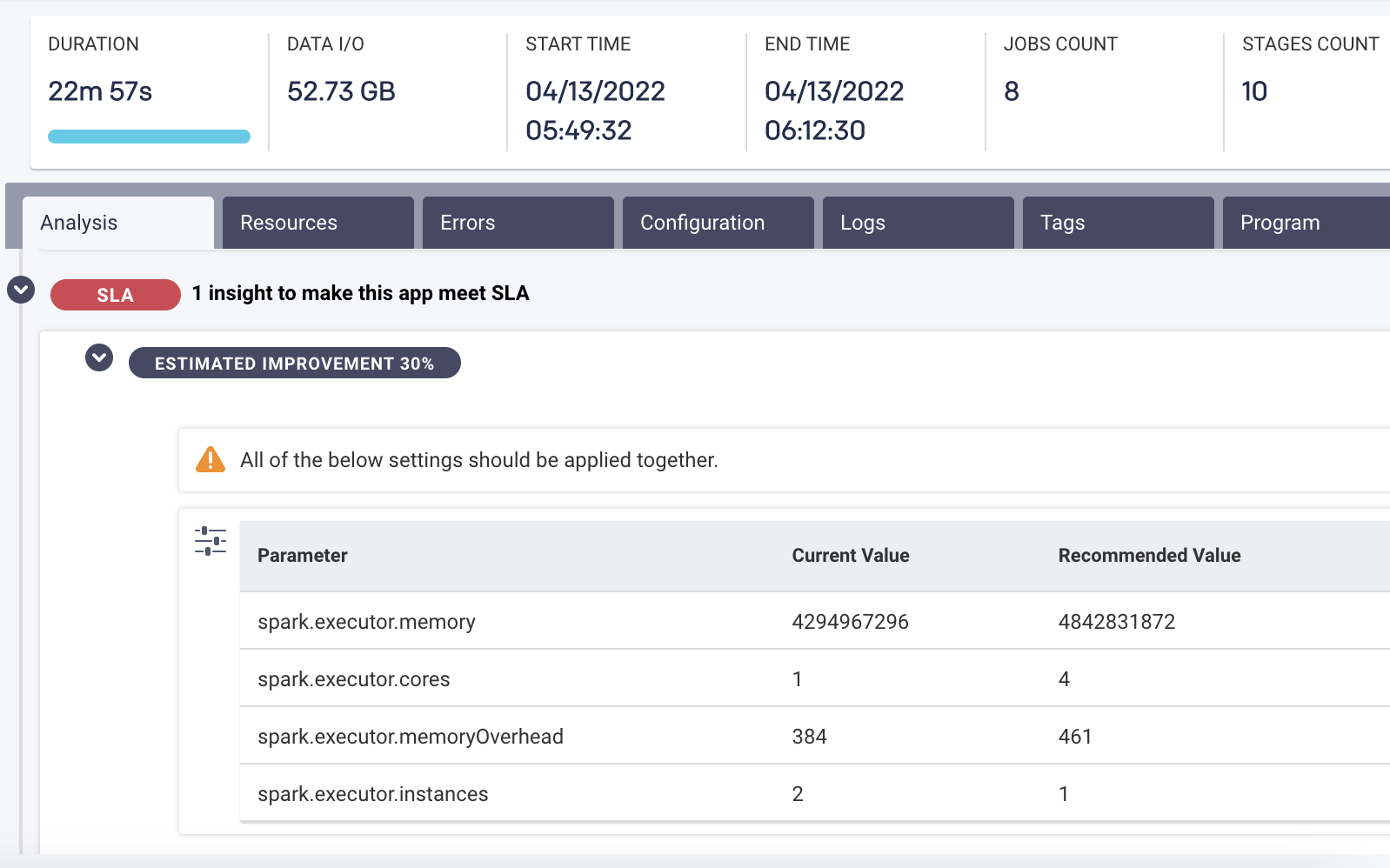
AI recommendations tell you exactly what to do to optimize for performance.
Observability is all about context. Traditional APM provides observability in context for web applications, but not for data applications and pipelines. But Unravel does. Its telemetry, correlation, anomaly detection, root cause analysis capabilities, and AI-powered remediation recommendations are all by design built specifically to understand, troubleshoot, and optimize modern data workloads.
If you want to know more about Unravel Data, you can get a free health check report to unlock your data environment or contact us.