
Articles
- AI & Automation
Unravel launches free Snowflake native app Read press release

Unravel launches free Snowflake native app Read press release











“Unravel cut our cloud data costs by 70% in six months—and keep them down.”
Learn More
“Equifax receives over 12 million online inquiries per day. Unravel has accelerated data product innovation and delivery.”
Learn More
“Unravel helped us improve the platform resiliency and availability multiple fold.”
Learn More












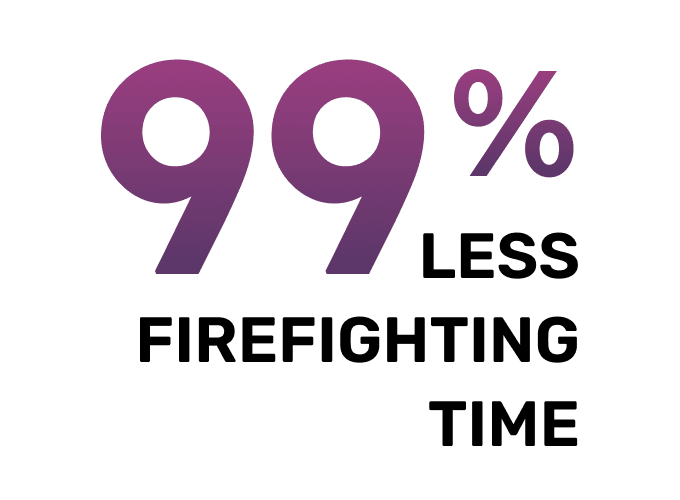
"We cut costs by 70% in the first 6 months."
HEAD OF DATA PLATFORM OPTIMIZATION Global Logistics Company
Unravel began as a research project at Duke University in 2015, initially focusing on recommending optimized configurations for Hadoop MapReduce jobs to enhance performance. Over time, Unravel has expanded its capabilities by developing AI solutions that improve cost efficiency and workload performance across a wide range of technologies, including Databricks, Snowflake, Spark on Kubernetes, BigQuery, EMR, and more. These advancements enable Unravel to deliver precise insights and measurable savings to its users.
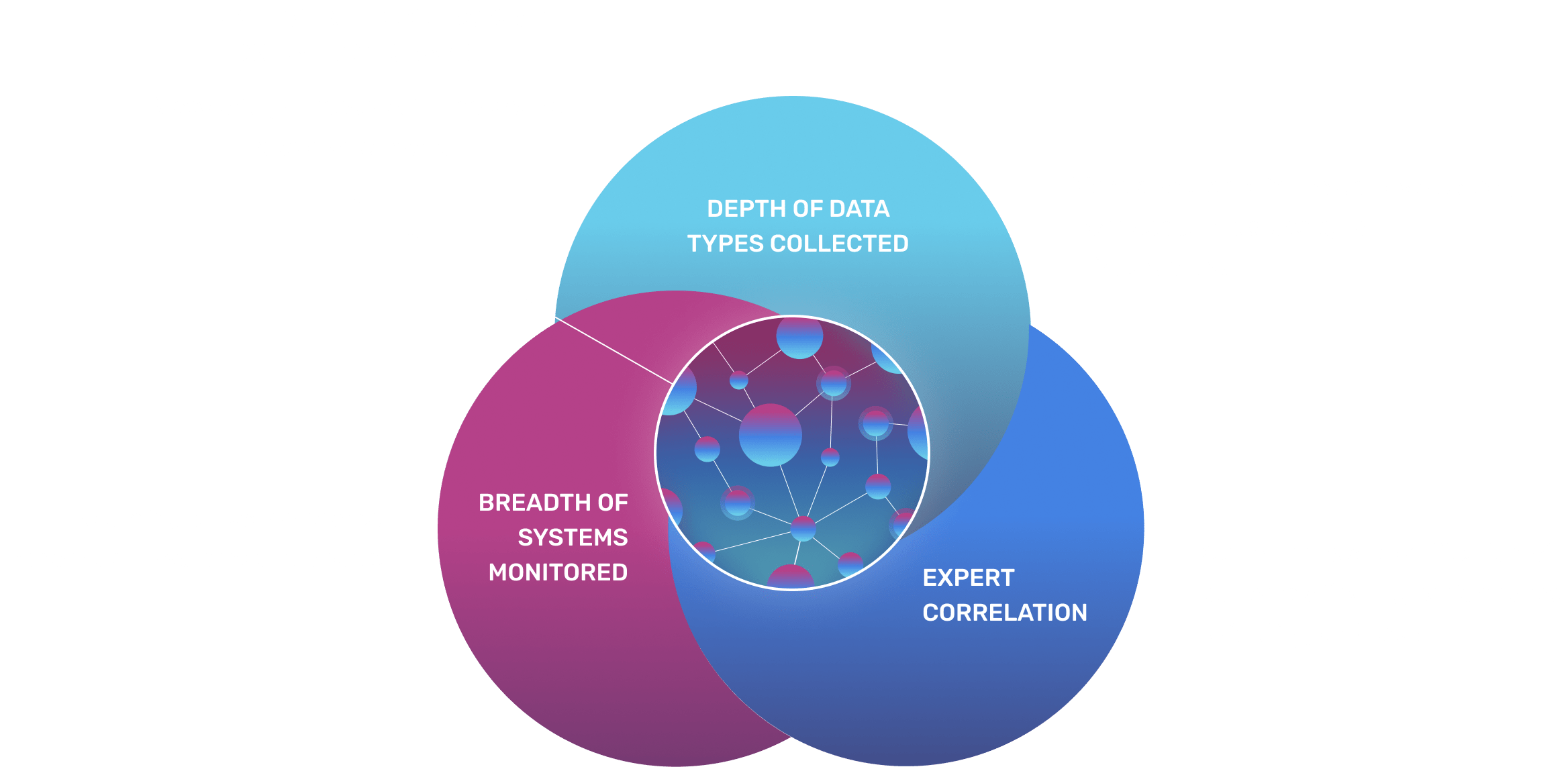
Unravel has extensive experience in developing a comprehensive knowledge graph alongside AI and ML techniques for cost and performance optimization. It analyzes a full stack of host metrics and telemetry data—including query metadata, compute details (e.g., warehouses, clusters), storage metadata, and network metadata—to pinpoint the root causes of inefficiencies and recommend actionable improvements. Unravel’s proven expertise is reflected in its success with numerous Fortune 500 companies and other leading enterprises across diverse industries, addressing real-world challenges and delivering measurable results.
Unravel leverages a knowledge graph that integrates a wide range of cloud and operational data to deliver precise, actionable insights. Our AI’s deep learning capabilities are continuously enhanced by analyzing vast datasets across various cloud environments, keeping us at the forefront of emerging trends in cost management.
The knowledge graph encompasses metadata on cloud spending, resource utilization, workload characteristics, and configuration settings across multiple cloud platforms. This rich, interconnected data enables Unravel’s AI to generate accurate, targeted recommendations that effectively address real-world challenges in cloud operations.
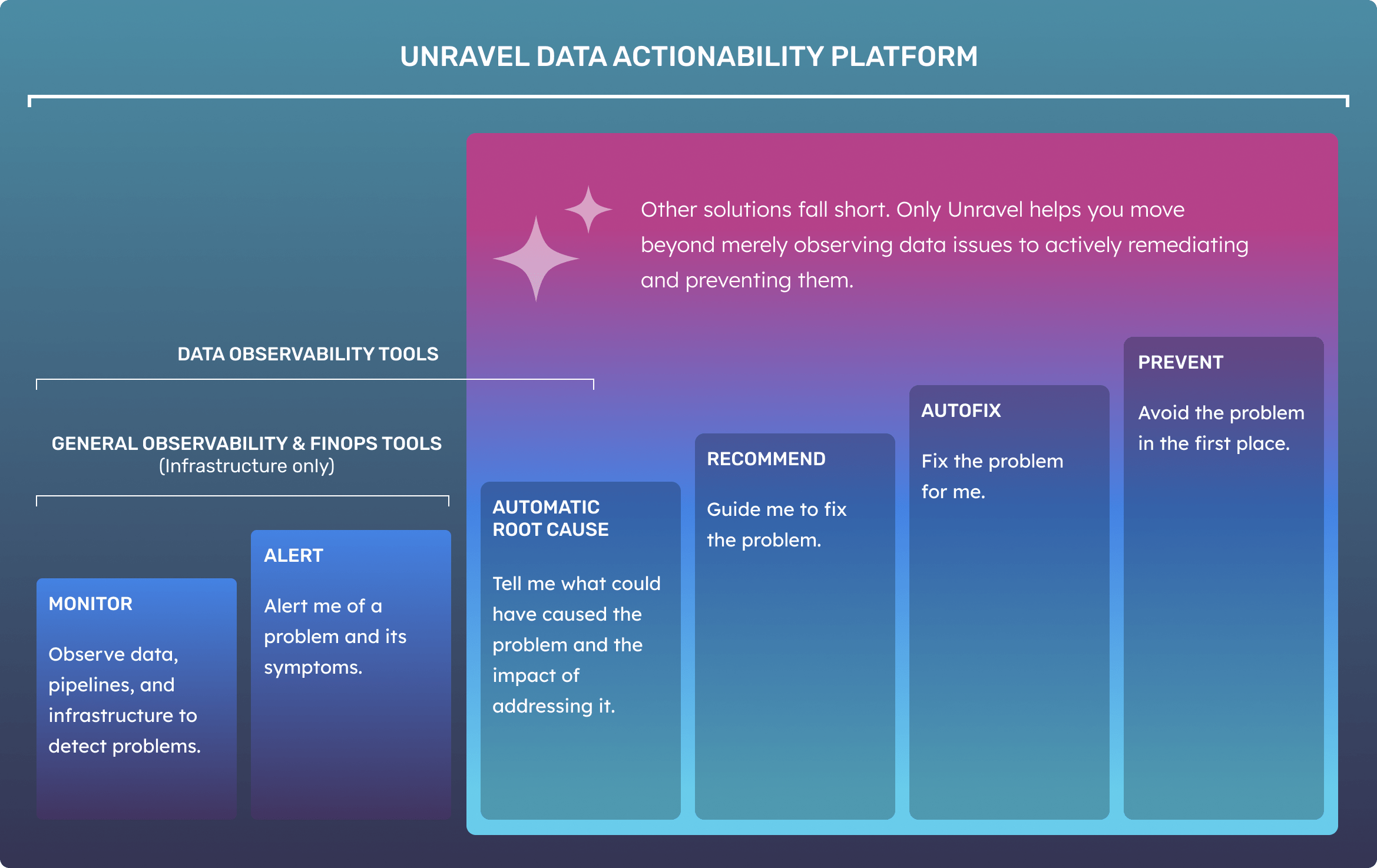
Unravel stands out among FinOps and data observability solutions by excelling in all three FinOps stages: inform, optimize, and operate. Beyond merely providing cost information at the account, project, business unit, or Line of Business (LoB) levels, Unravel integrates app-level usage data to offer detailed chargeback and trend analysis at the workspace, cluster, and user levels.
For optimization, Unravel’s AI pinpoints root causes across queries, compute, and storage, delivering specific recommendations for query rewrites and adjustments to warehouse, cluster, and table configurations, ensuring actionable and effective cost savings.
Unravel prioritizes data privacy by ensuring that no data is sent back to your data warehouse, data lake, or lakehouse. Any data transfers are fully controlled by your team and occur only when explicitly configured. Our platform collects only job execution and configuration-related metadata, which is then utilized to generate tailored insights and actionable recommendations. This design upholds strict privacy standards while delivering valuable performance and cost optimization guidance.
Unravel is committed to security and focused on keeping our clients and their data safe. The solution designed by Unravel manages customer data based on the five SOC trust services criteria — security, availability, processing integrity, confidentiality, and privacy. We use TLS encryption, the same standard used by secure websites, to secure data in transit. Unravel is SOC 2-compliant, and has earned a Service Organization Control (SOC) 2, Type II certification.