Unravel provides unprecedented SQL observability, intelligence, and tuning for cloud-scale SQL operations, and for SQL queries that complete faster and more predictably.
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Try for Free
Unravel delivers peak SQL cluster performance and reliability for your SQL applications and queries
Unravel provides rich metrics and runtime analytics of SQL operations across the big data stack. From Hive, Spark SQL, Impala, and Hbase, to the new generation SQL engines in the cloud, Unravel provides maximum visibility with the essential context needed to understand how complex SQL queries, database clusters, and applications execute in distributed environments. Get a free health check report to unlock your data environment.
** DO NOT REMOVE Hidden Margin Required **
SQL cluster intelligence across the full data stack
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Instantly observe, understand and optimize SQL server cluster behavior.
Unravel displays the runtime characteristics of SQL operations in the Spark/Hadoop in an intuitive user interface. SQL teams can quickly drill down to get detailed operational context and AI-powered recommendations for their SQL server clusters from Unravel. Unravel Spark capabilities include:
Visibility into the essential SQL and NoSQL technologies including Impala, HBase, Hive, and Spark SQL.
Optimizing SQL in the cloud with upcoming support for services like Amazon Redshift, Athena, Microsoft SQL DW, and Google BigQuery.
Accessing analytics and KPIs for completed SQL workloads at the query, segment, and step level.
** DO NOT REMOVE Hidden Margin Required **
Deep insights about Hive delivered in plain language
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
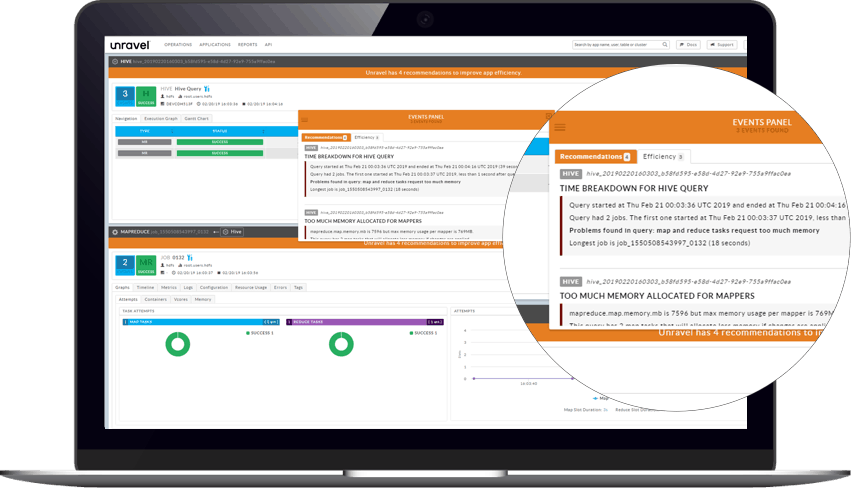
Know exactly what is going on in your Hive metastores, queries and applications.
Unravel enables you to work the way you intuitively want to work, with time saving automation and plain language recommendations and insights such as:
Hive query failures due to broken pipe, incorrect header check, and out of memory exceptions.
Hive queries that are killed or have failed with lots of wasted work, failed tasks, or wasted resources.
Hive is using too few or too many mappers/reducers or that they are requesting too much memory.
** DO NOT REMOVE Hidden Margin Required **
Insights into SQL query plans and the tables they work on
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
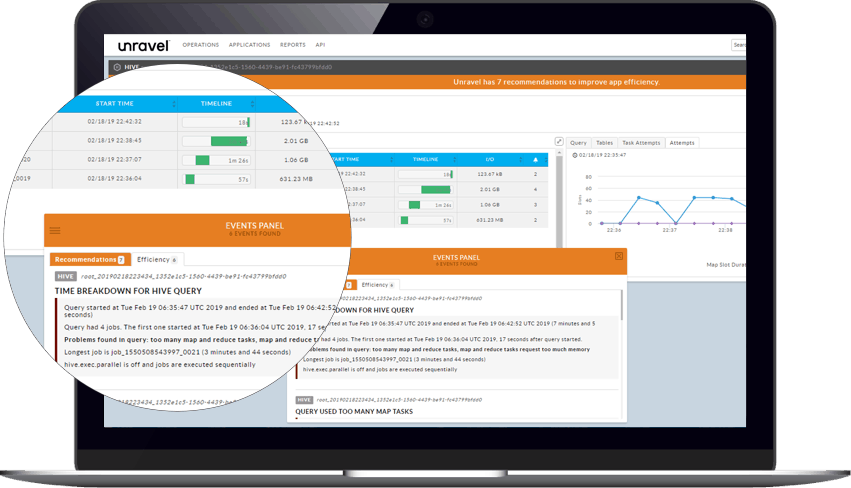
Insights into multi-stage, distributed SQL applications and queries.
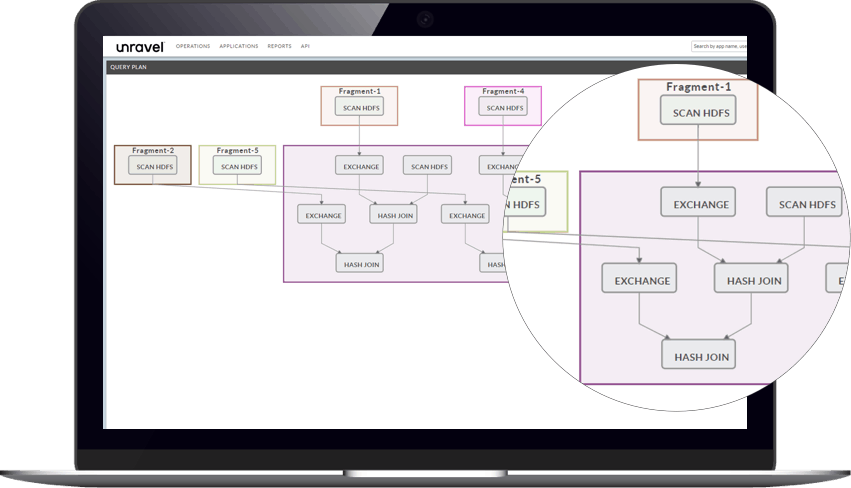
Unravel provides vital intelligence about how SQL queries are planned and executed, as well as how they affect and are affected by the organization of tables and data files. Among the key insights are:
Insight into the distribution of queries and fragments across the cluster and a time breakdown of all of the stages of execution.
Graphical representations of complex SQL query plans and insights into how and when they are executed.
Details of how SQL queries are executed with recommendations and insights into memory management, resource usage, etc.