

This blog was originally published by Unravel CEO Kunal Agarwal on LinkedIn in September 2022.
I was chatting with Sanjeev Mohan, Principal and Founder of SanjMo Consulting and former Research Vice President at Gartner, about how the emergence of DataOps is changing people’s idea of what “data observability” means. Not in any semantic sense or a definitional war of words, but in terms of what data teams need to stay on top of an increasingly complex modern data stack. While much ink has been spilled over how data observability is much more than just data profiling and quality monitoring, until only very recently the term has pretty much been restricted to mean observing the condition of the data itself.
But now DataOps teams are thinking about data observability more comprehensively as embracing other “flavors” of observability like application and pipeline performance, operational observability into how the entire platform or system is running end-to-end, and business observability aspects such as ROI and—most significantly—FinOps insights to govern and control escalating cloud costs.
That’s what we at Unravel call DataOps observability.
Data teams are getting bogged down
Data teams are struggling, overwhelmed by the increased volume, velocity, variety, and complexity of today’s data workloads. These data applications are simultaneously becoming ever more difficult to manage and ever more business-critical. And as more workloads migrate to the cloud, team leaders are finding that costs are getting out of control—often leading to migration initiatives stalling out completely because of budget overruns.
The way data teams are doing things today isn’t working.
Data engineers and operations teams spend way too much time firefighting “by hand.” Something like 70-75% of their time is spent tracking down and resolving problems through manual detective work and a lot of trial and error. And with 20x more people creating data applications than fixing them when something goes wrong, the backlog of trouble tickets gets longer, SLAs get missed, friction among teams creeps in, and the finger-pointing and blame game begins.
This less-than-ideal situation is a natural consequence of inherent process bottlenecks and working in silos. There are only a handful of experts who can untangle the wires to figure out what’s going on, so invariably problems get thrown “over the wall” to them. Self-service remediation and optimization is just a pipe dream. Different team members each use their own point tools, seeing only part of the overall picture, and everybody gets a different answer to the same problem. Communication and collaboration among the team breaks down, and you’re left operating in a Tower of Babel.
Download here
Accelerating next-gen DataOps observability
These problems aren’t new. DataOps teams are facing some of the same general challenges as their DevOps counterparts did a decade ago. Just as DevOps united the practice of software development and operations and transformed the application lifecycle, today’s data teams need the same observability but tailored to their unique needs. And while application performance management (APM) vendors have done a good job of collecting, extracting, and correlating details into a single pane of glass for web applications, they’re designed for web applications and give data teams only a fraction of what they need.

System point tools and cloud provider tools all provide some of the information data teams need, but not all. Most of this information is hidden in plain sight—it just hasn’t been extracted, correlated, and analyzed by a single system designed specifically for data teams.
That’s where Unravel comes in.
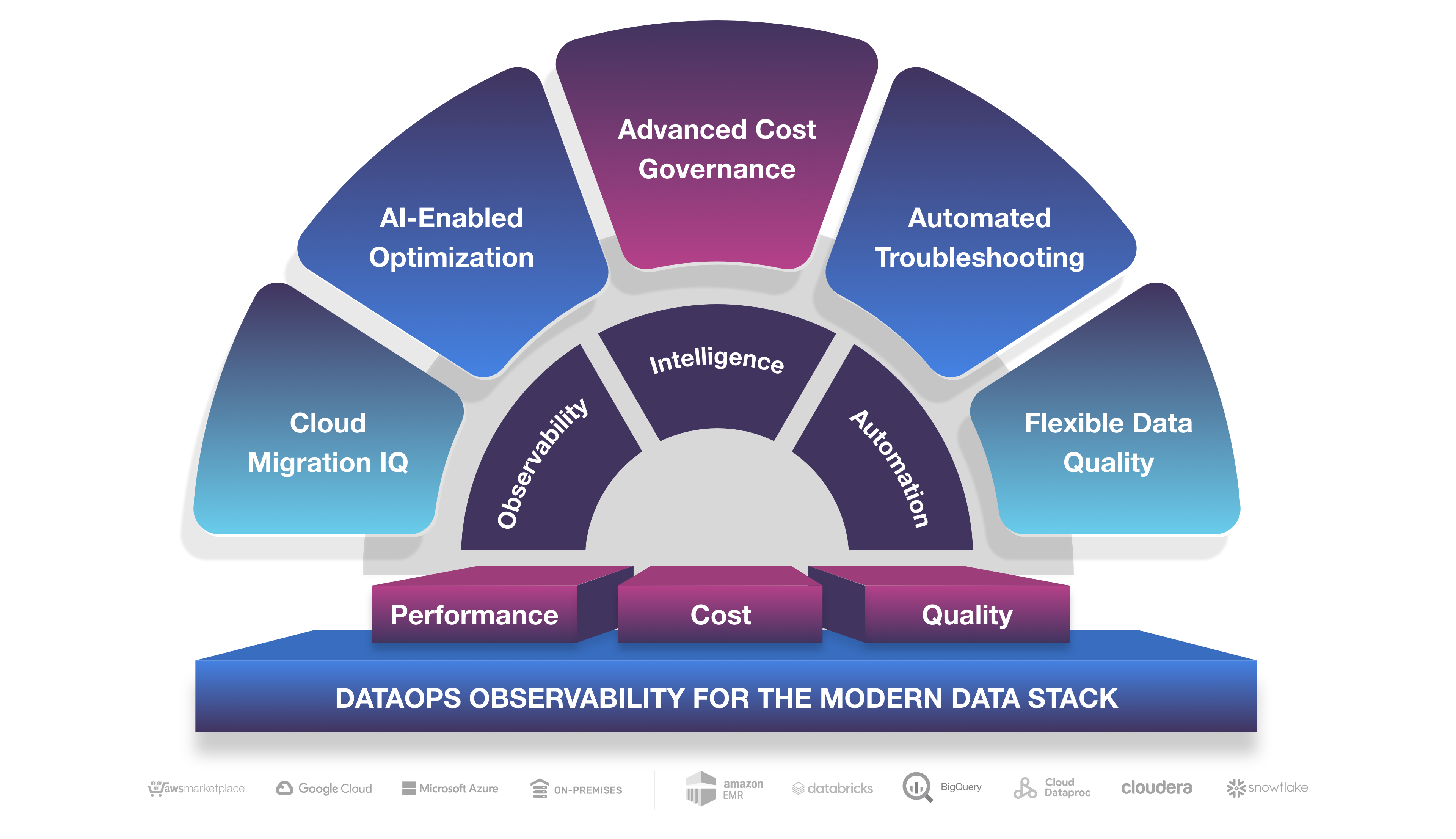
Data teams need what Unravel delivers—observability designed to show data application/pipeline performance, cost, and quality coupled with precise, prescriptive fixes that will allow you to quickly and efficiently solve the problem and get on to the real business of analyzing data. Our AI-powered solution helps enterprises realize greater return on their investment in the modern data stack by delivering faster troubleshooting, better performance to meet service level agreements, self-service features that allow applications to get out of development and into production faster and more reliably, and reduced cloud costs.
I’m excited, therefore, to share that earlier this week, we closed a $50 million Series D round of funding that will allow us to take DataOps observability to the next level and extend the Unravel platform to help connect the dots from every system in the modern data stack—within and across some of the most popular data ecosystems.
Unlocking the door to success
By empowering data teams to spend more time on innovation and less time firefighting, Unravel helps data teams take a page out of their software counterparts’ playbook and tackle their problems with a solution that goes beyond observability—to not just show you what’s going on and why, but actually tell you exactly what to do about it. It’s time for true DataOps observability.
To learn more about how Unravel Data is helping data teams tackle some of today’s most complex modern data stack challenges, visit: www.unraveldata.com.